Yarn提交实践指南
Yarn-Session 实践
注册 Session 集群
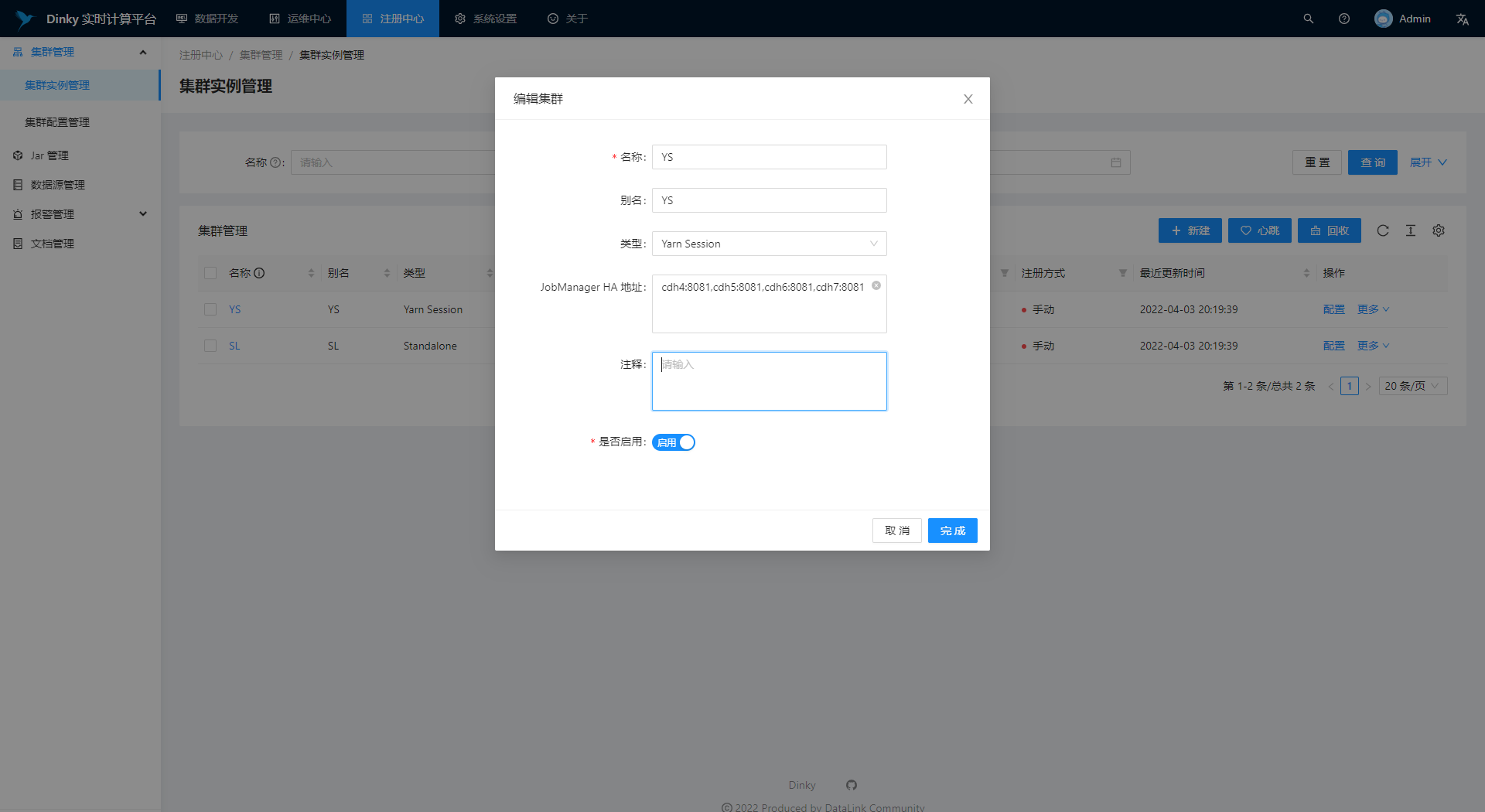
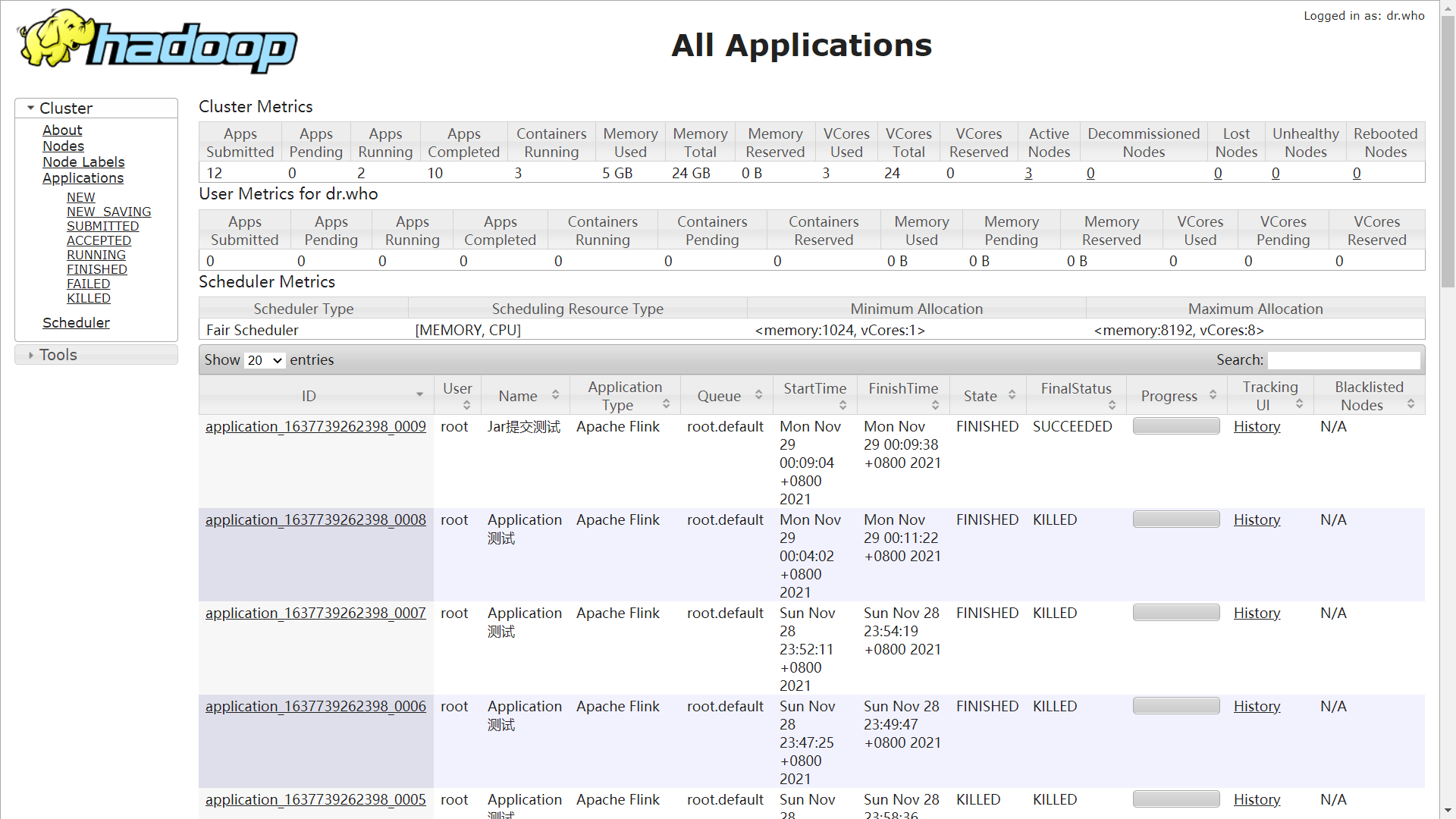
创建 Session 集群
进入集群中心进行远程集群的注册。点击新建按钮配置远程集群的参数。图中示例配置了一个 Flink on Yarn 的高可用集群,其中 JobManager HA 地址需要填写集群中所有可能被作为 JobManager 的 RestAPI 地址,多个地址间使用英文逗号分隔。表单提交时可能需要较长时间的等待,因为 dlink 正在努力的计算当前活跃的 JobManager 地址。
保存成功后,页面将展示出当前的 JobManager 地址以及被注册集群的版本号,状态为正常时表示可用。
注意:只有具备 JobManager 实例的 Flink 集群才可以被成功注册到 dlink 中。( Yarn-Per-Job 和 Yarn-Application 也具有 JobManager,当然也可以手动注册,但无法提交任务)
如状态异常时,请检查被注册的 Flink 集群地址是否能正常访问,默认端口号为8081,可能更改配置后发生了变化,查看位置为 Flink Web 的 JobManager 的 Configuration 中的 rest 相关属性。
执行 Hello World
万物都具有 Hello World 的第一步,当然 Dinky 也是具有的。我们选取了基于 datagen 的流查询作为第一行 Flink Sql。具体如下:
CREATE TABLE Orders (
order_number BIGINT,
price DECIMAL(32,2),
buyer ROW<first_name STRING, last_name STRING>,
order_time TIMESTAMP(3)
) WITH (
'connector' = 'datagen',
'rows-per-second' = '1'
);
select order_number,price,order_time from Orders
该例子使用到了 datagen,需要在 dlink 的 plugins 目录下添加 flink-table.jar。
点击 数据开发 进入开发页面:
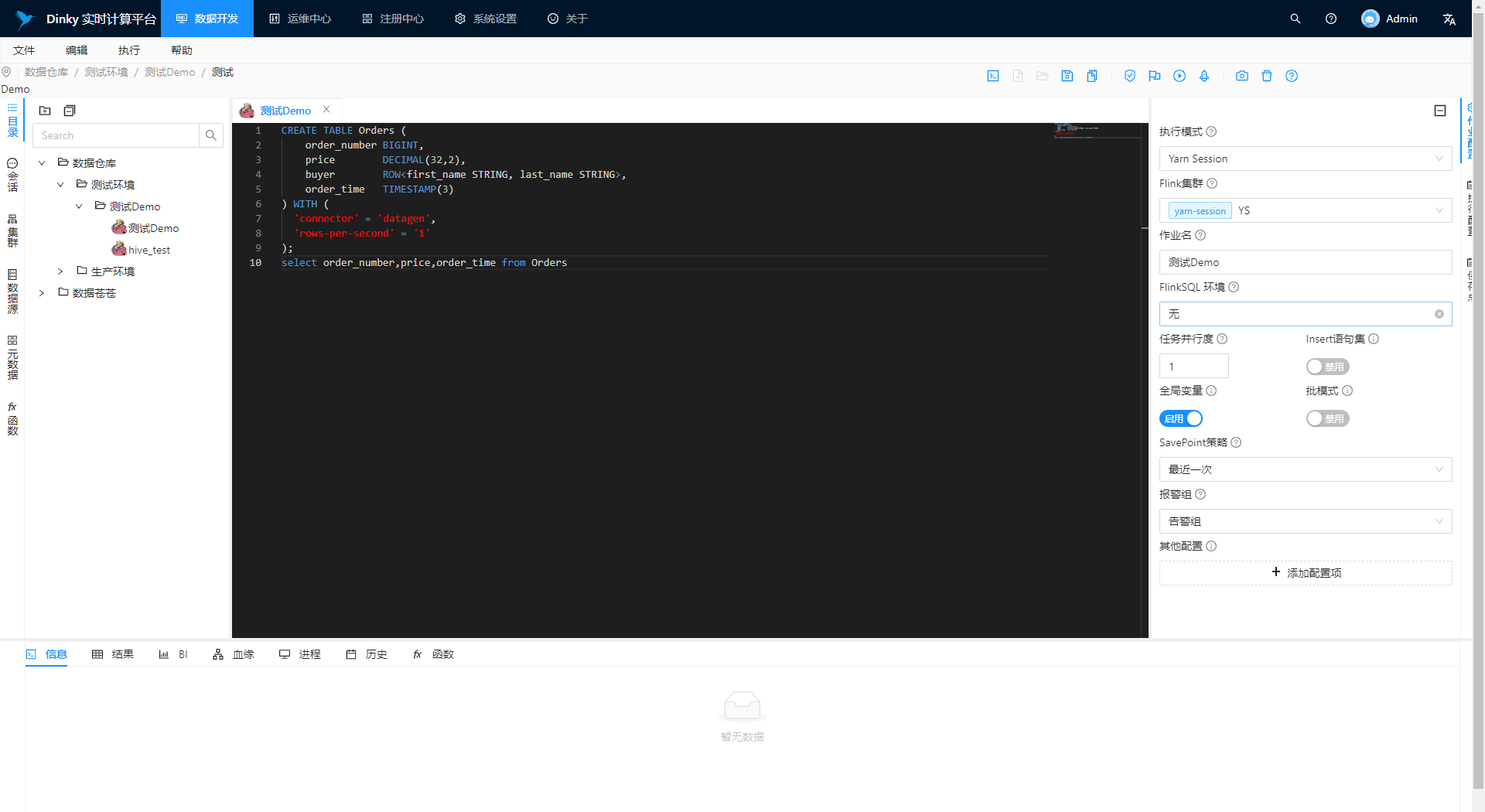
在中央的编辑器中编辑 Flink Sql。
右边作业配置:
- 执行模式:选中 Yarn-session;
- Flink 集群:选中上文注册的测试集群;
- SavePoint 策略:选中禁用;
- 按需进行其他配置。
右边执行配置:
- 预览结果:启用;
- 远程执行:启用。
点击快捷操作栏的三角号按钮同步执行该 FlinkSQL 任务。
预览数据
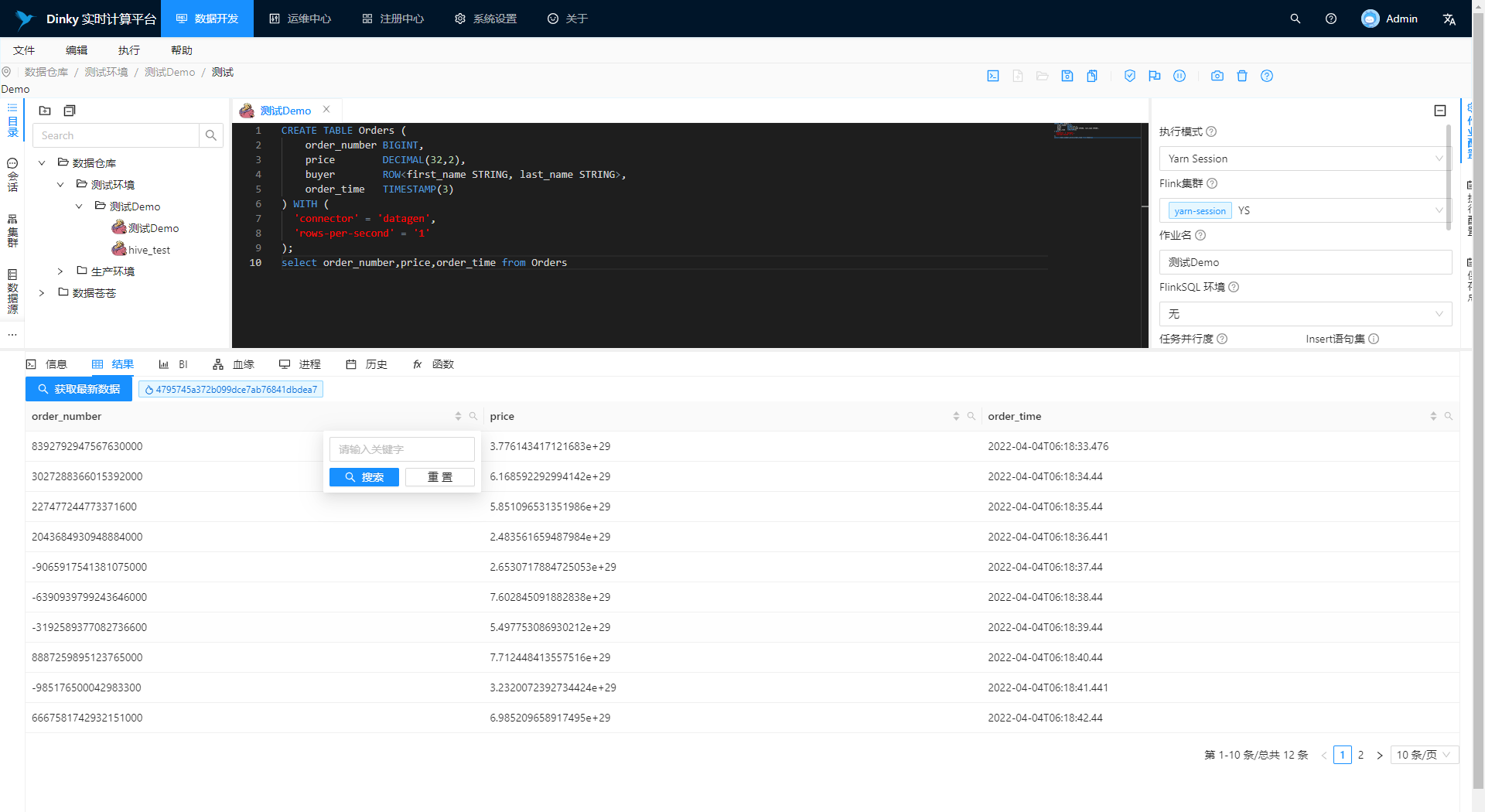
切换到历史选项卡点击刷新可以查看提交进度。切换到结果选项卡,等待片刻点击获取最新数据即可预览 SELECT。
停止任务
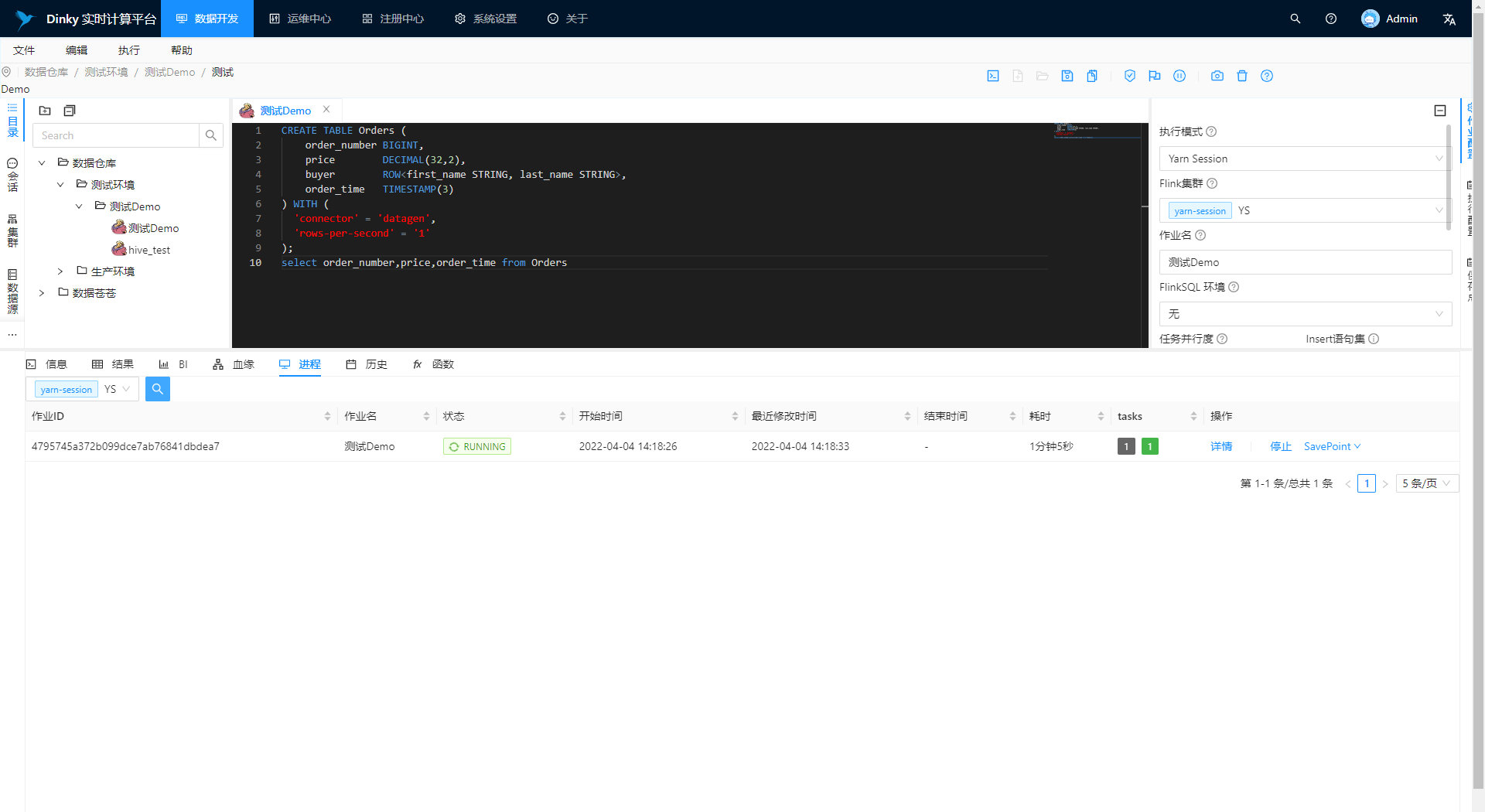
切换到进程选项卡,选则对应的集群实例,查询当前任务,可执行停止操作。
Yarn-Per-Job 实践
注册集群配置
进入集群中心——集群配置,注册配置。

- Hadoop 配置文件路径:指定配置文件路径(末尾无/),需要包含以下文件:core-site.xml,hdfs-site.xml,yarn-site.xml;
- Flink 配置 lib 路径:指定 lib 的 hdfs 路径(末尾无/),需要包含 Flink 运行时的所有依赖,即 flink 的 lib 目录下的所有 jar;
- Flink 配置文件路径:指定配置文件 flink-conf.yaml 的具体路径(末尾无/);
- 按需配置其他参数(重写效果);
- 配置基本信息(标识、名称等);
- 点击测试或者保存。
执行升级版 Hello World
之前的 hello world 是个 SELECT 任务,改良下变为 INSERT 任务:
CREATE TABLE Orders (
order_number INT,
price DECIMAL(32,2),
order_time TIMESTAMP(3)
) WITH (
'connector' = 'datagen',
'rows-per-second' = '1',
'fields.order_number.kind' = 'sequence',
'fields.order_number.start' = '1',
'fields.order_number.end' = '1000'
);
CREATE TABLE pt (
ordertotal INT,
numtotal INT
) WITH (
'connector' = 'print'
);
insert into pt select 1 as ordertotal ,sum(order_number)*2 as numtotal from Orders
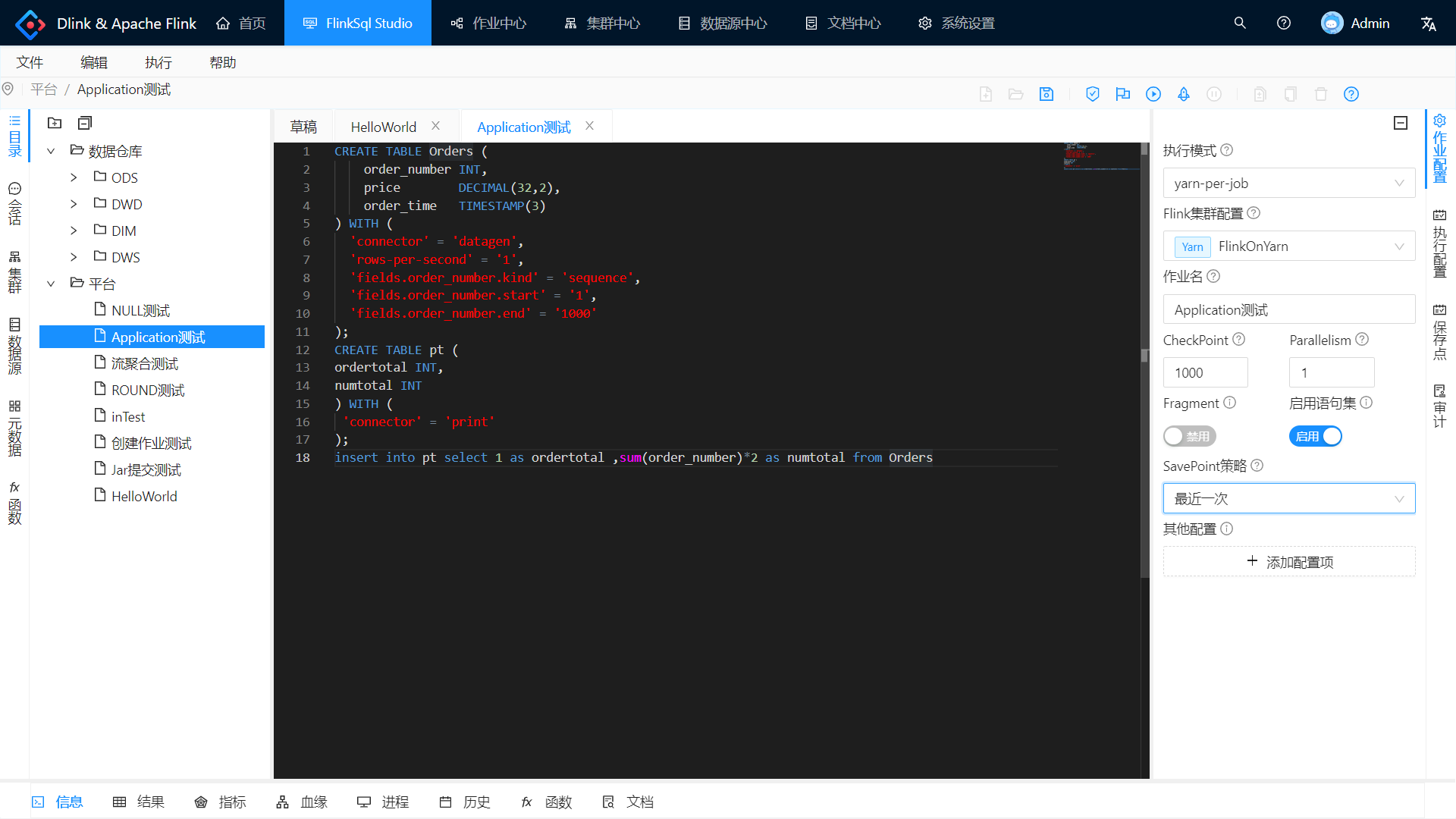
编写 Flink SQL;
作业配置:
- 执行模式:选中 yarn-per-job ;
- Flink 集群配置:选中刚刚注册的配置;
- SavePoint 策略:选中最近一次。
快捷操作栏:
- 点击保存按钮保存当前所有配置;
- 点击小火箭异步提交作业。
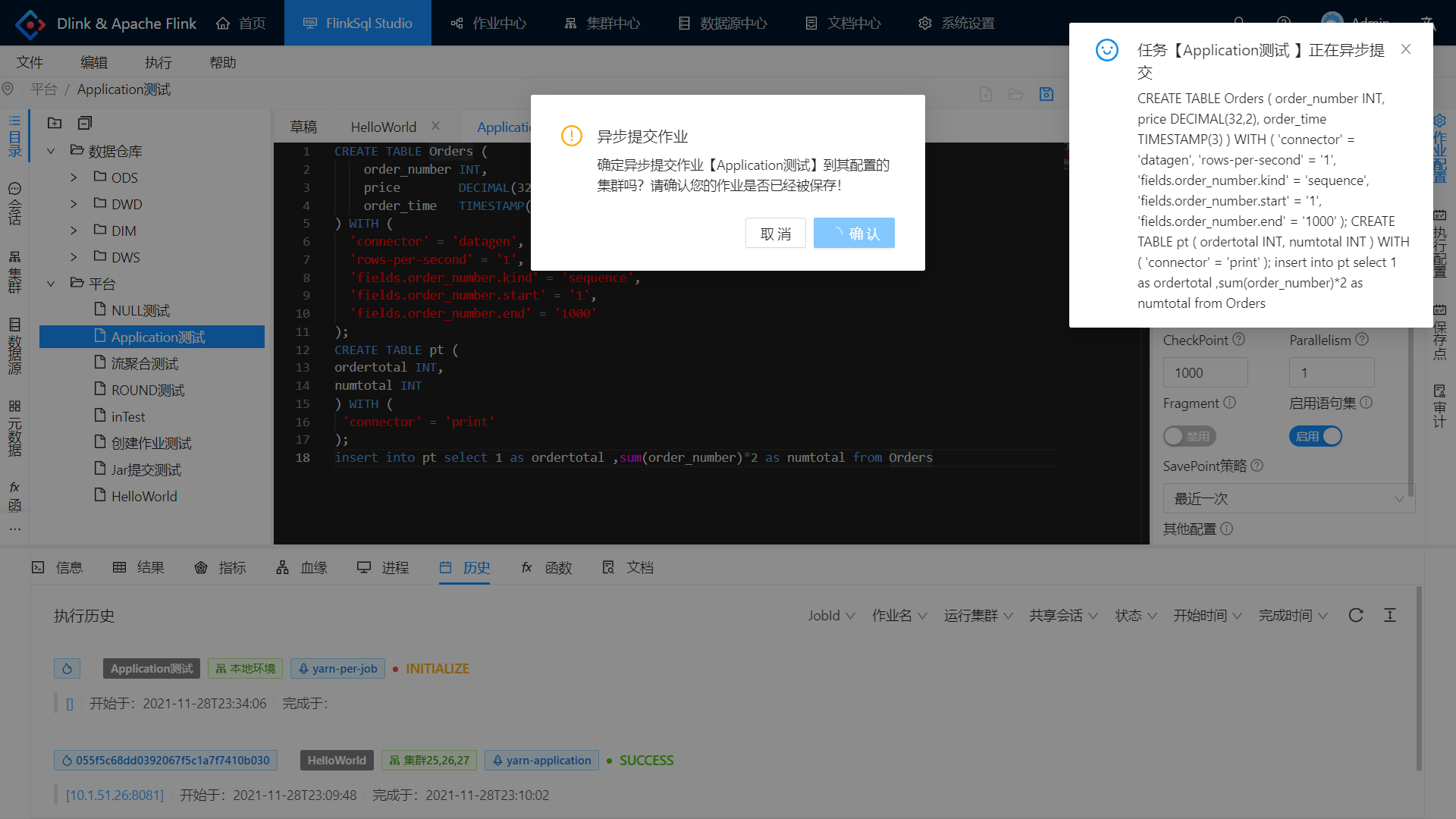
注意,执行历史需要手动刷新。
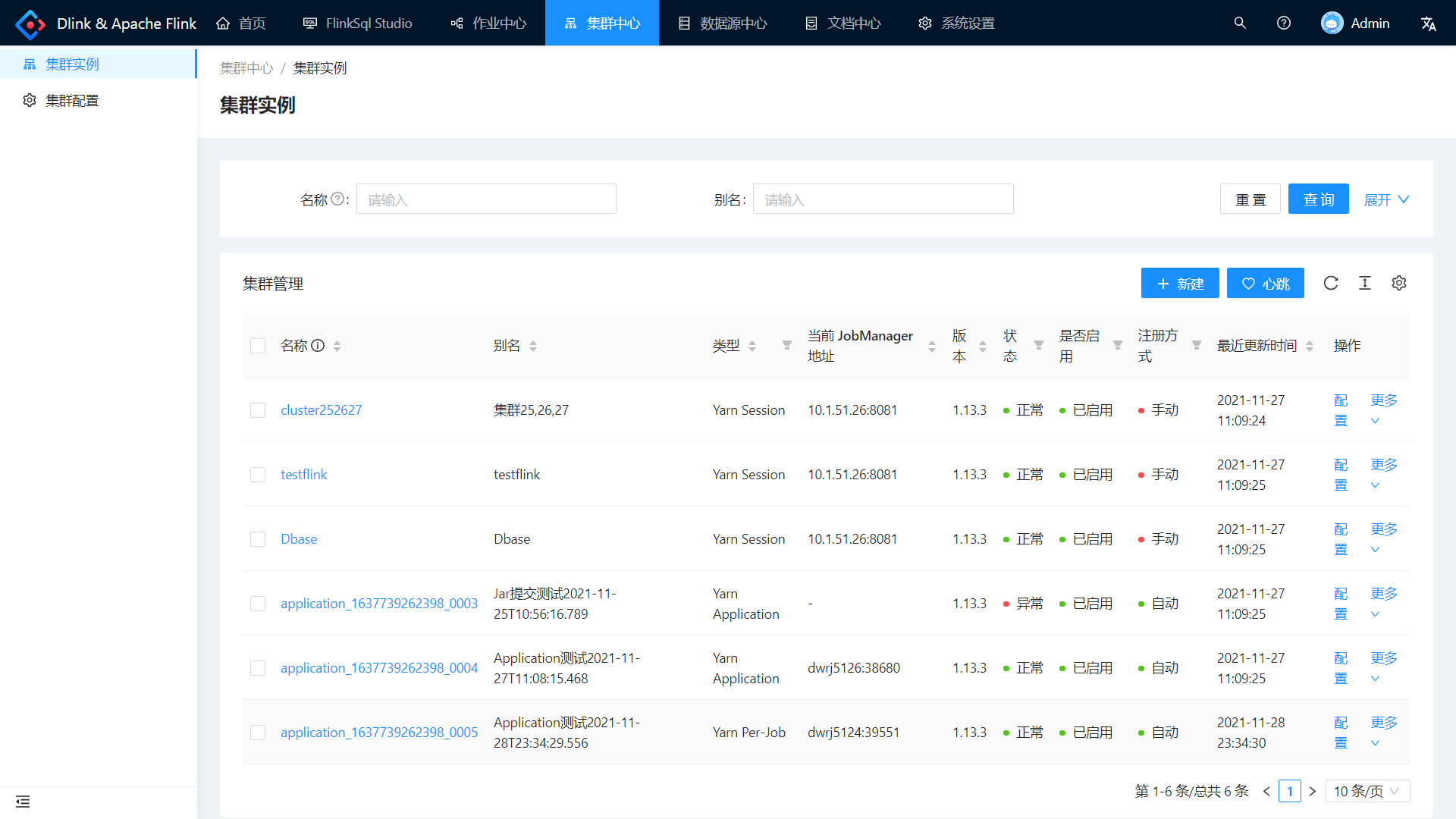
自动注册集群
点击集群中心——集群实例,即可发现自动注册的 Per-Job 集群。
查看 Flink Web UI
提交成功后,点击历史的蓝色地址即可快速打开 Flink Web UI地址。
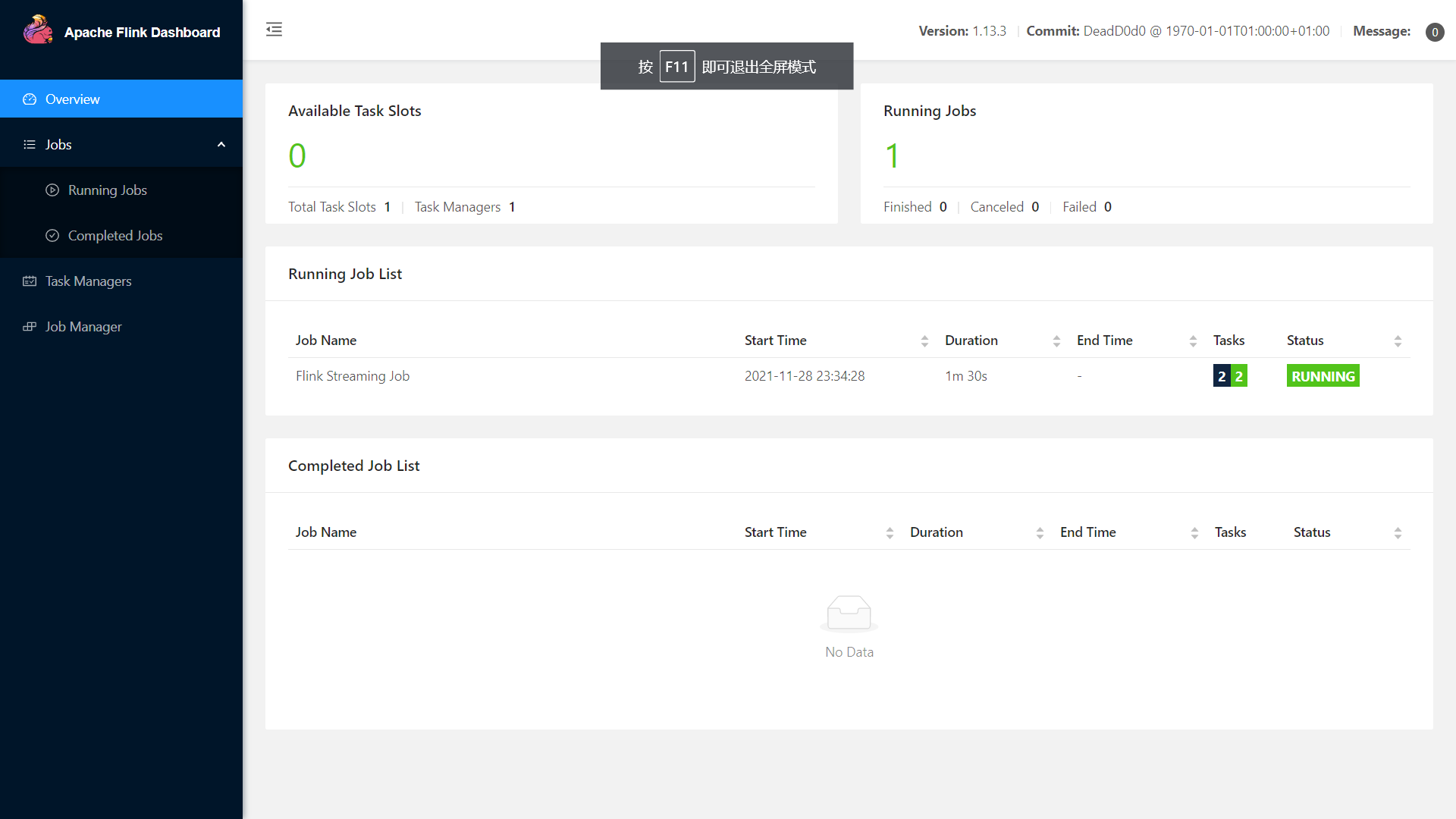
从 Savepoint 处停止
在进程选项卡中选择自动注册的 Per-Job 集群,查看任务并 SavePoint-Cancel。
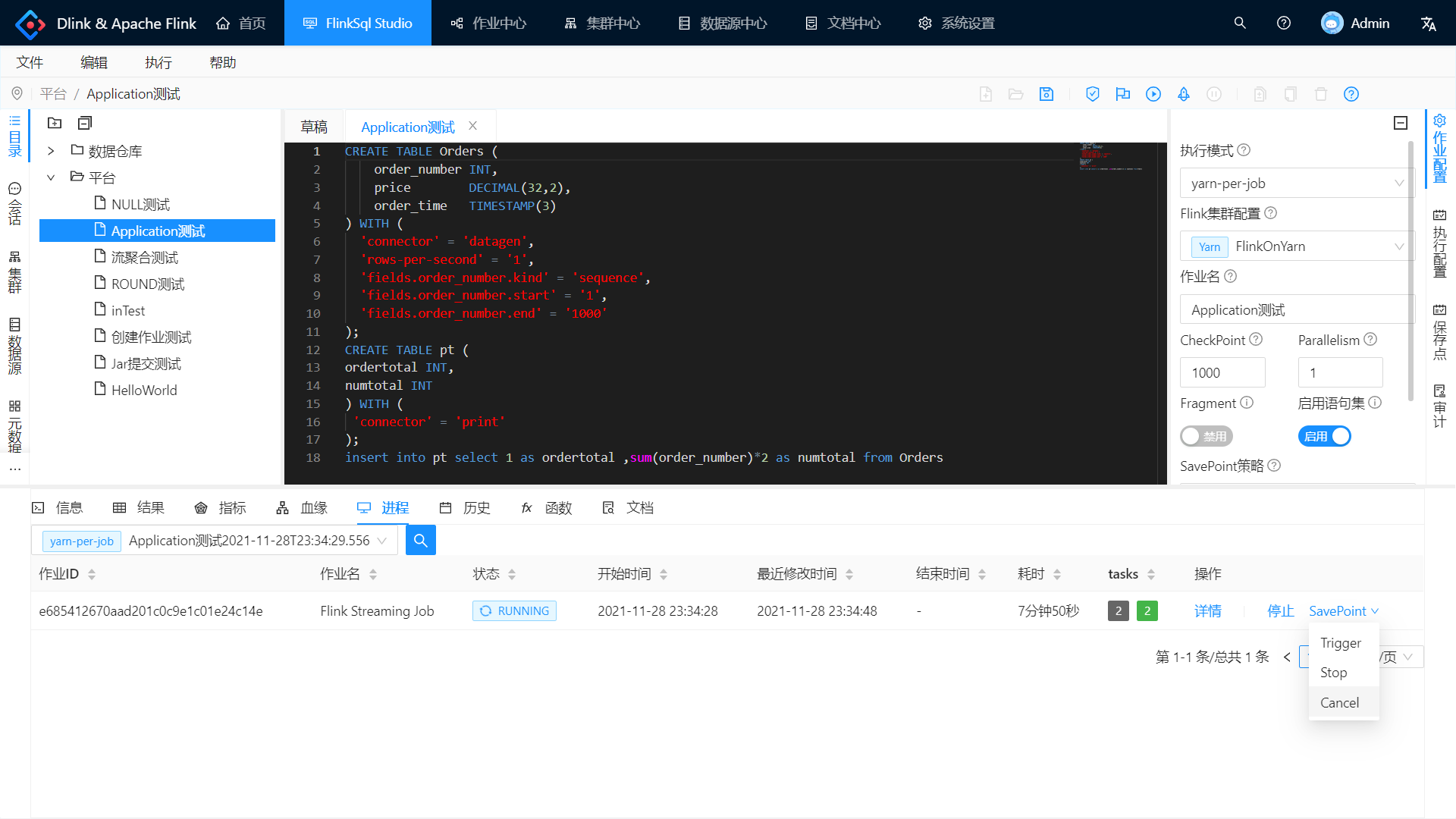
在右侧保存点选项卡可以查看该任务的所有 SavePoint 记录。
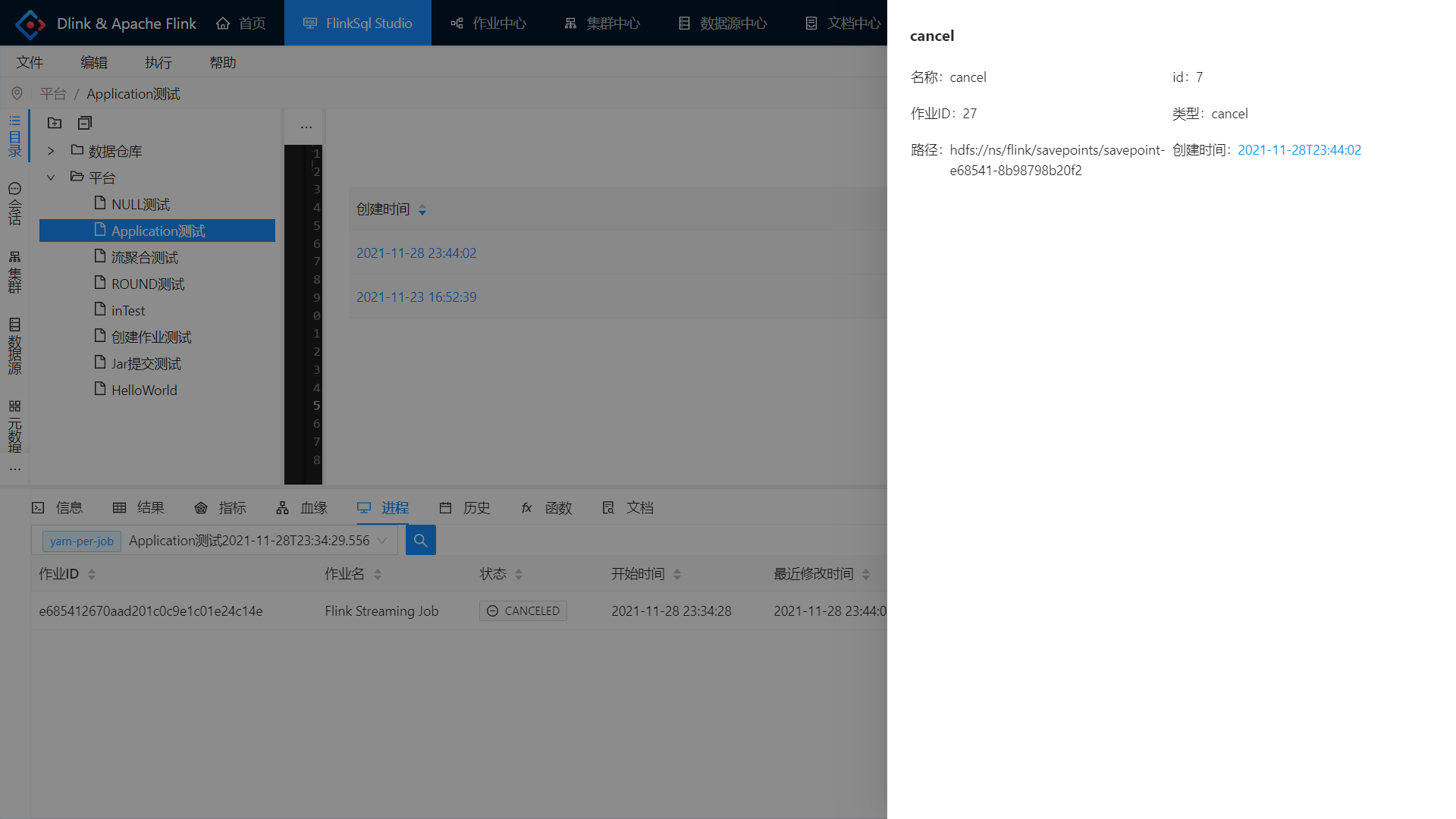
从 SavePoint 处启动
再次点击小火箭提交任务。
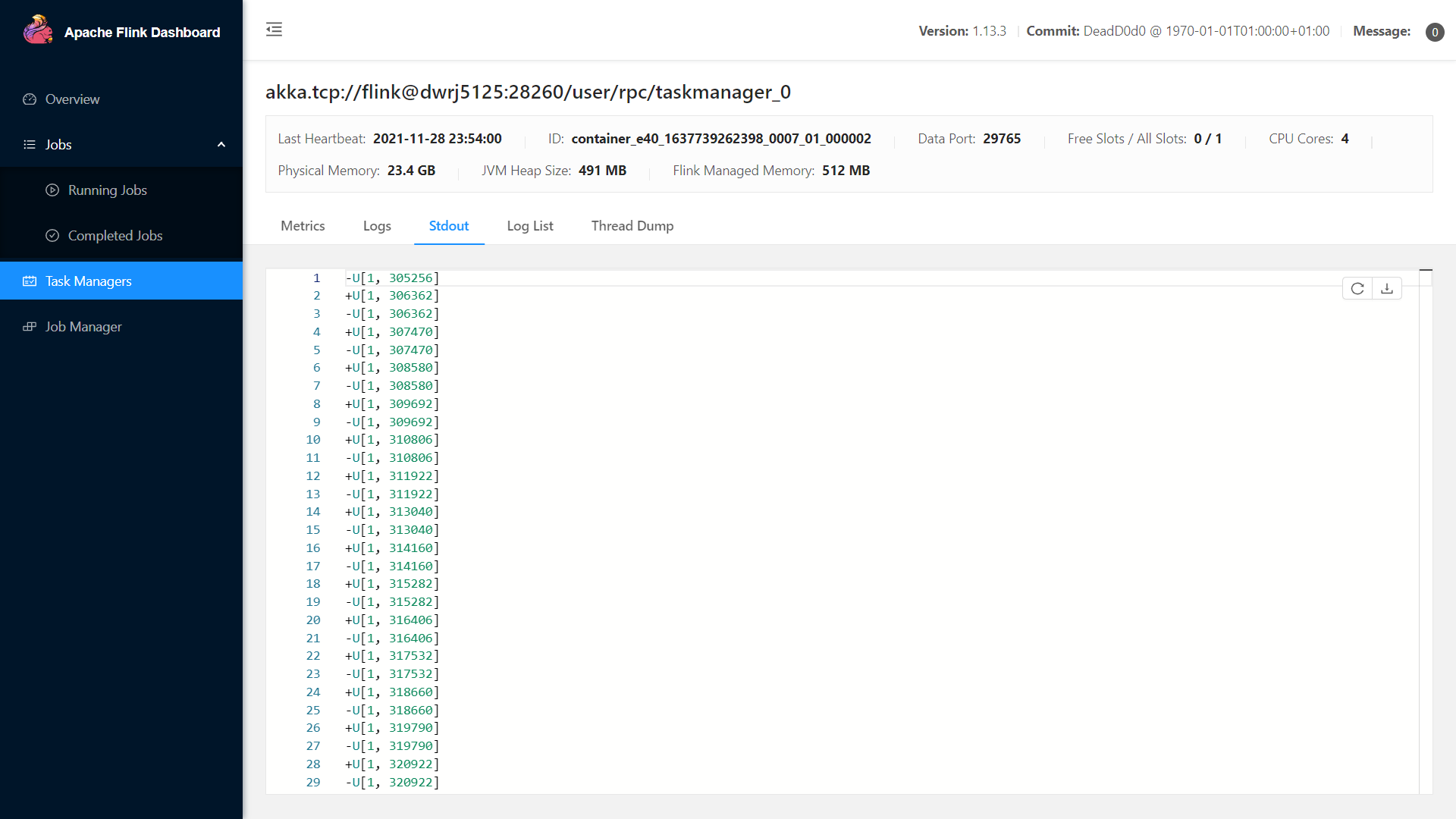 查看对应 Flink Web UI,从 Stdout 输出中证实 SavePoint 恢复成功。
查看对应 Flink Web UI,从 Stdout 输出中证实 SavePoint 恢复成功。
Yarn-Application 实践
注册集群配置
使用之前注册的集群配置即可。
上传 dlink-app.jar
第一次使用时,需要将 dlink-app.jar 上传到 hdfs 指定目录,目录可修改如下:
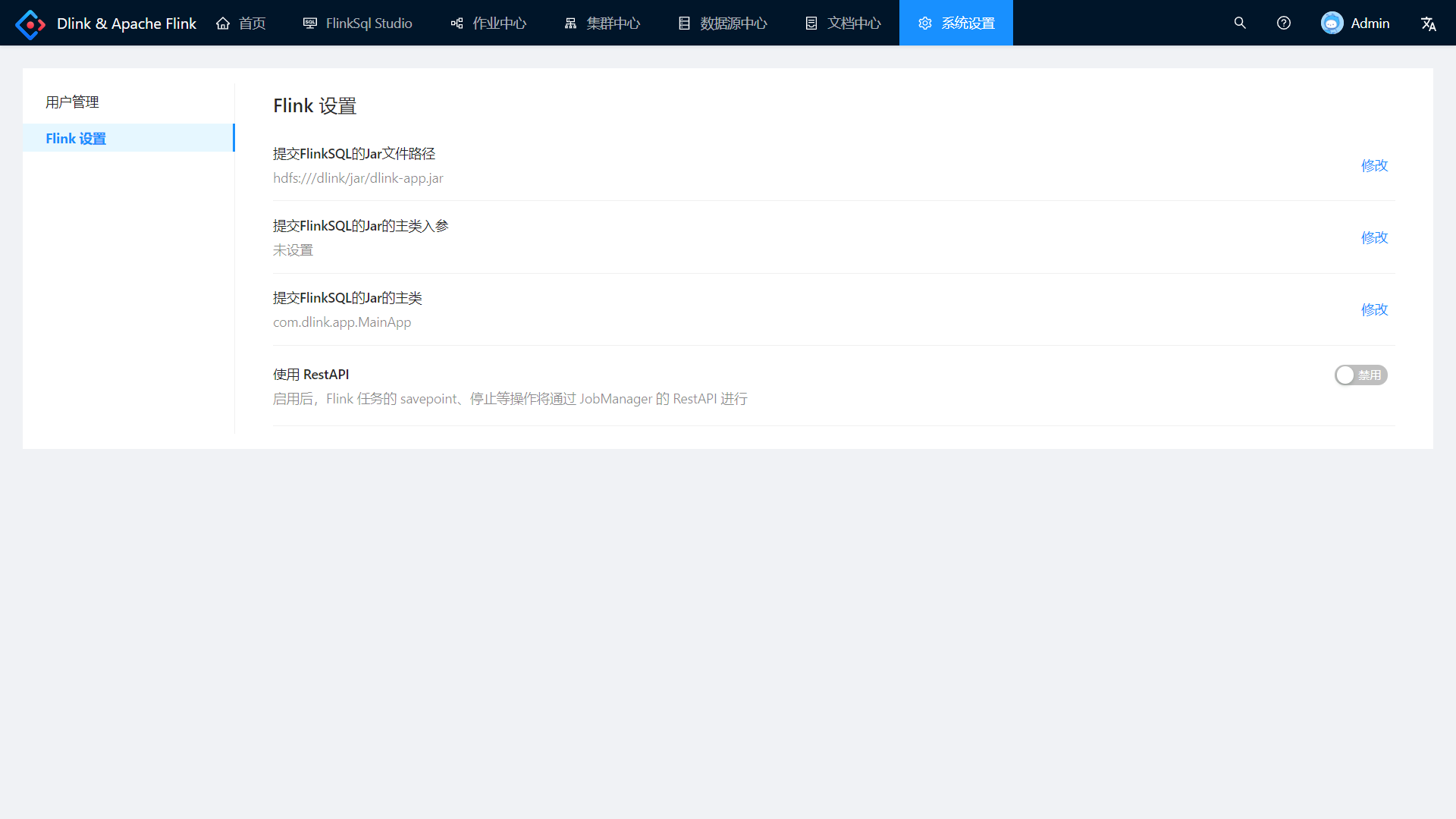
50070 端口 浏览文件系统如下:
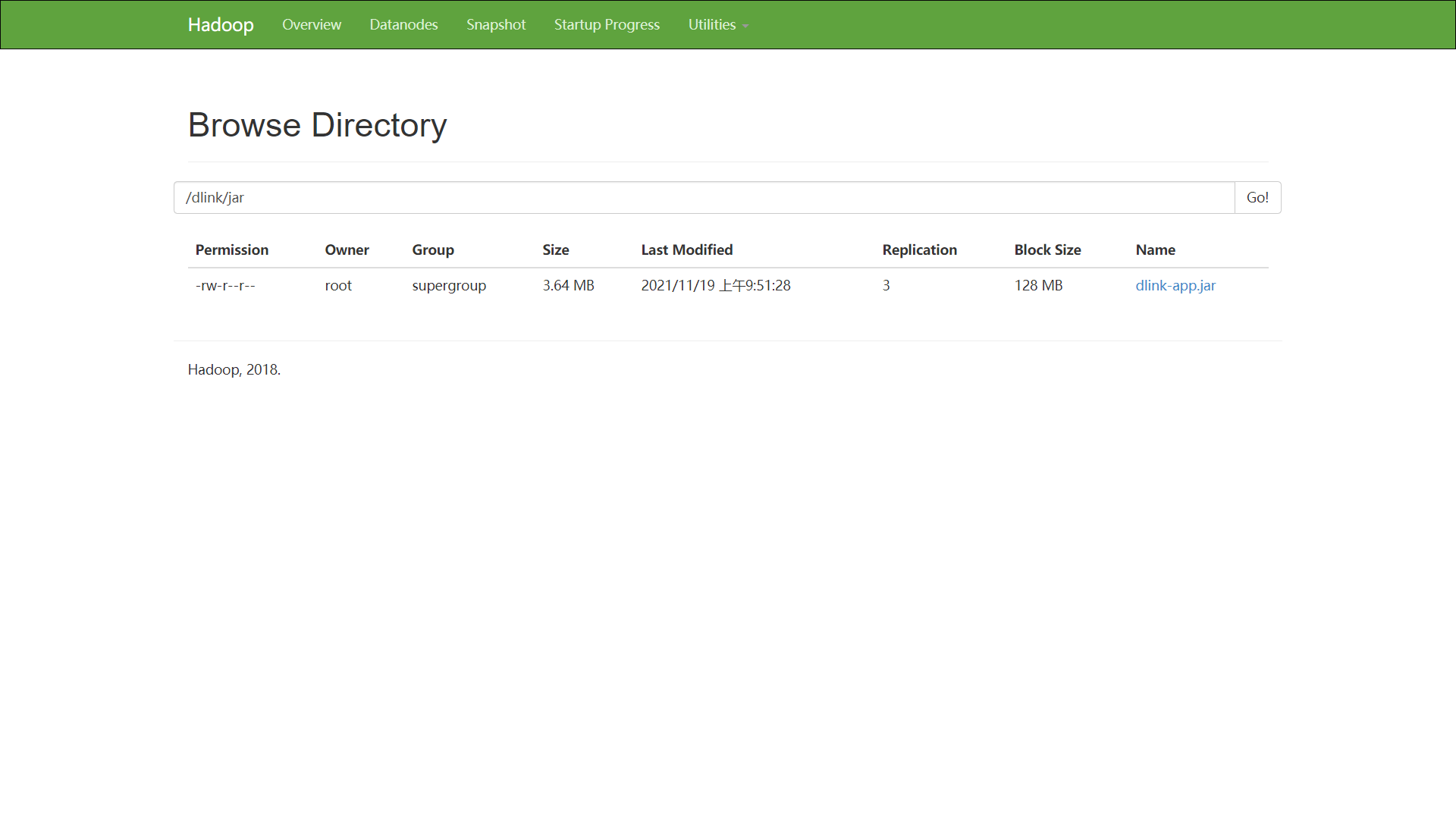
执行升级版 Hello World
作业配置:
- 执行模式:选中 yarn-application ;
快捷操作栏:
- 点击保存按钮保存当前所有配置;
- 点击小火箭异步提交作业。
其他同 Per-Job
其他操作同 yarn-per-job ,本文不再做描述。
提交 User Jar
作业中心—— Jar 管理,注册 User Jar 配置。
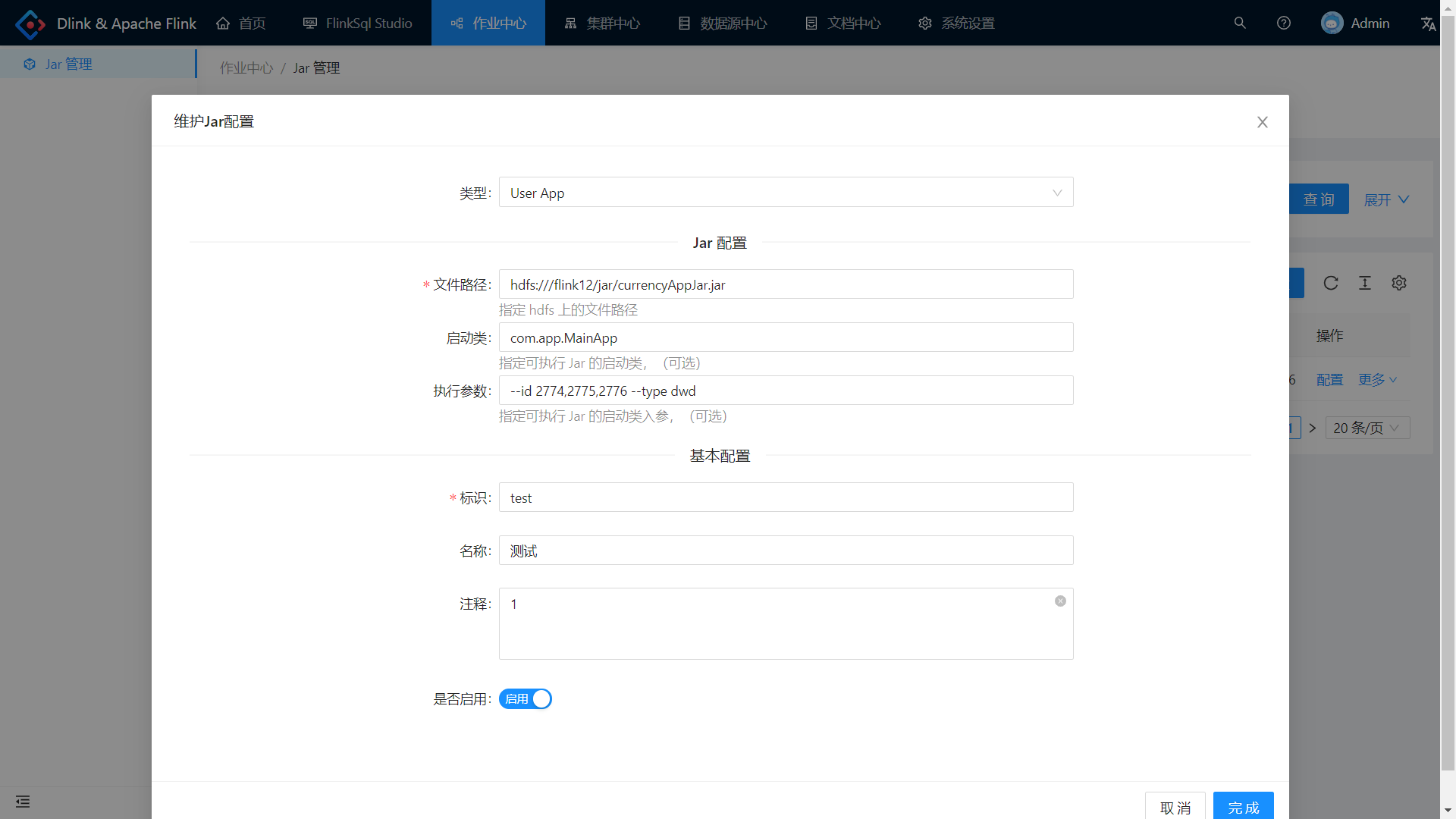
右边作业配置的可执行 Jar 选择刚刚注册的 Jar 配置,保存后点击小火箭提交作业。
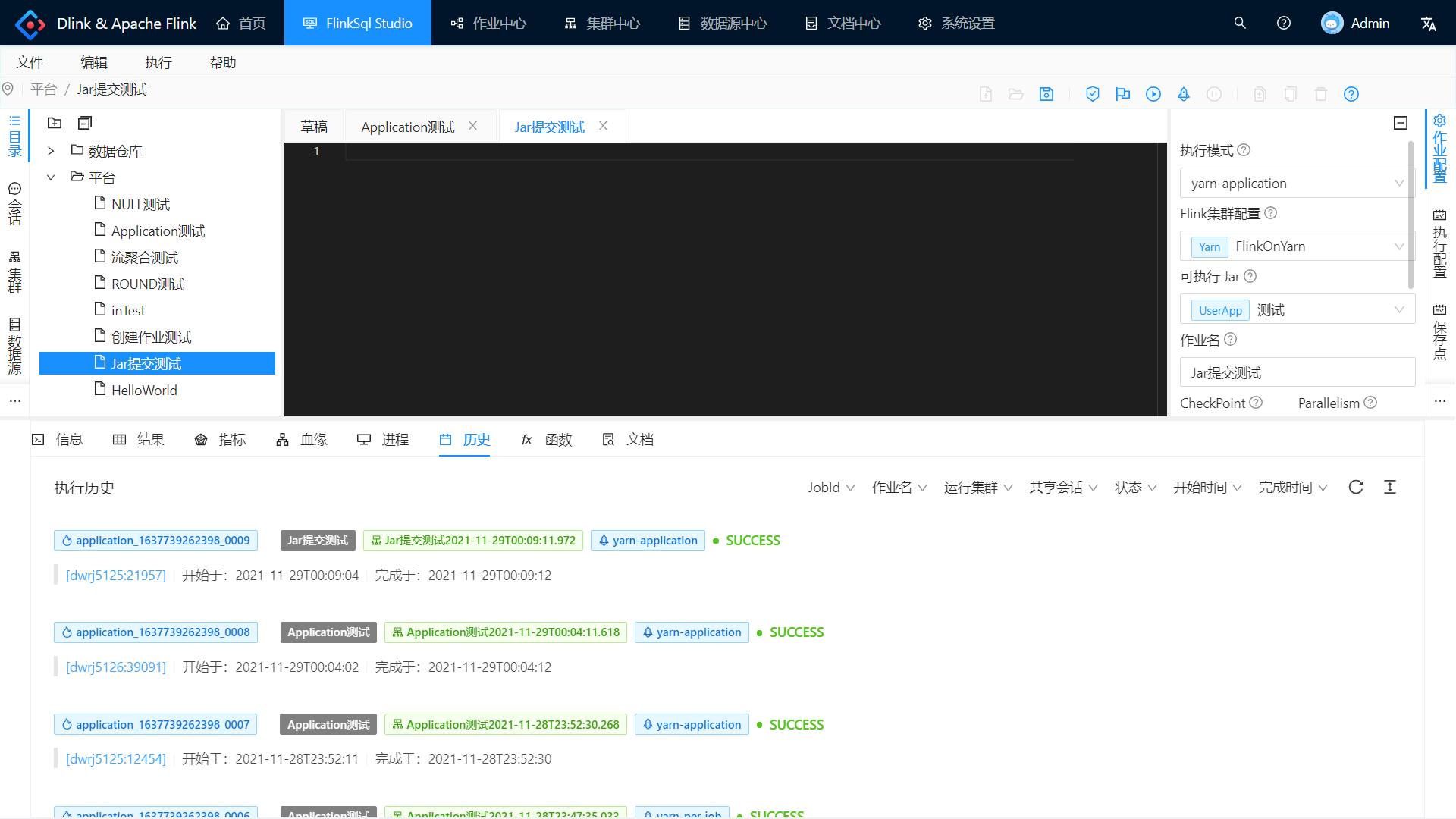
由于提交了个批作业,Yarn 可以发现已经执行完成并销毁集群了。