Redis
1. 场景
1.1 通过flink cdc同步mysql数据库数据到redis;
1.2 通过flinlSql, 将kafka的数据关联 redis;
2. 组件准备
| 组件 | 版本 |
|---|---|
| flink | 1.14.4 |
| Flink-mysql-cdc | 2.2.1 |
| redis | 6.2.4 |
| Mysql | 5.7+ |
| Dinky | 0.6.6 |
| commons-pool2 | 2.11.0 |
| jedis | 3.3.0 |
| flink-connector-redis | 1.0.11 |
| flink-sql-connector-kafka | 2.12-1.14.4 |
温馨提示
commons-pool2, jedis 包, 是flink-connector-redis 的jar引用到了, 故添加上, 这两个maven仓库都能下载.或者您自己编译源码. 其中jedis的编译的版本比较旧了, 有更新的RC包, 安全起见, 如部署生产环境, 应自行编译flink-connector-redis, github地址: https://github.com/jeff-zou/flink-connector-redis 在此感谢jeff-zou大佬贡献的connector!
3. 部署
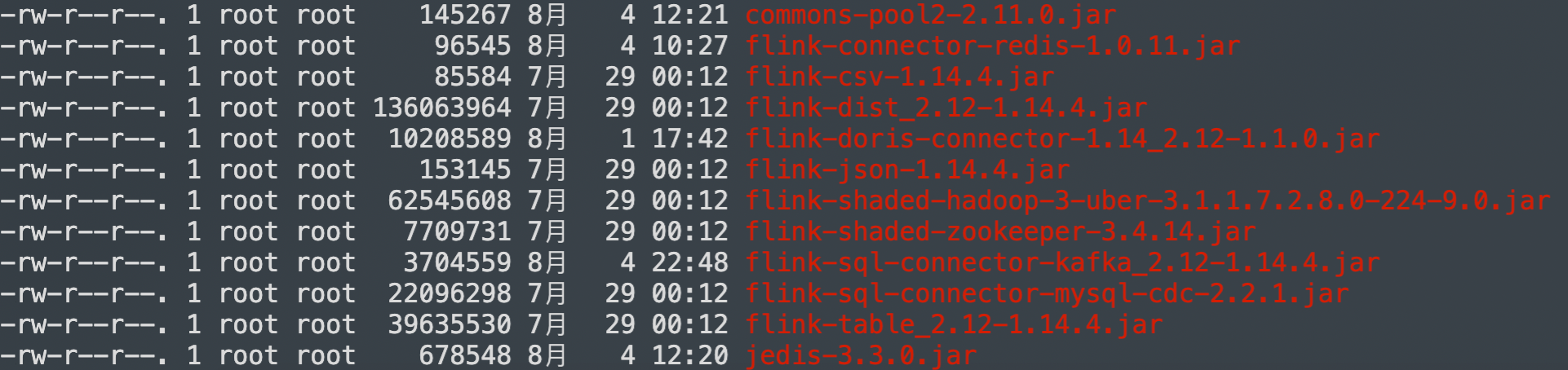
Dlink 的 plugins 下添加 commons-pool2-2.11.0.jar, jedis-3.3.0.jar, flink-connector-redis-1.0.11.jar, flink-sql-connector-kafka_2.12-1.14.4.jar, 重启 Dlink. flink standalone模式 或者 yarn 模式, 请自行往需要的地方添加依赖.
依赖图
场景1:
通过flink cdc同步更新mysql数据库数据到redis
1.1 准备需要同步的数据, 同步库 emp_1 下的employees_1,employees_2
create database emp_1;
CREATE TABLE IF NOT EXISTS `employees_1` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(50) NOT NULL,
`last_name` varchar(50) NOT NULL,
`gender` enum('M','F') NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
insert into employees_1 VALUES ("10", "1992-09-12", "cai", "kunkun", "M", "2022-09-22");
insert into employees_1 VALUES ("11", "1990-09-15", "wang", "meimei", "F", "2021-04-12");
CREATE TABLE IF NOT EXISTS `employees_2` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(50) NOT NULL,
`last_name` varchar(50) NOT NULL,
`gender` enum('M','F') NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
insert into employees_2 VALUES ("20", "1987-01-23", "huang", "menji", "M", "2000-03-04");
insert into employees_2 VALUES ("21", "1993-04-21", "lu", "benweiniubi", "M", "2022-05-06");
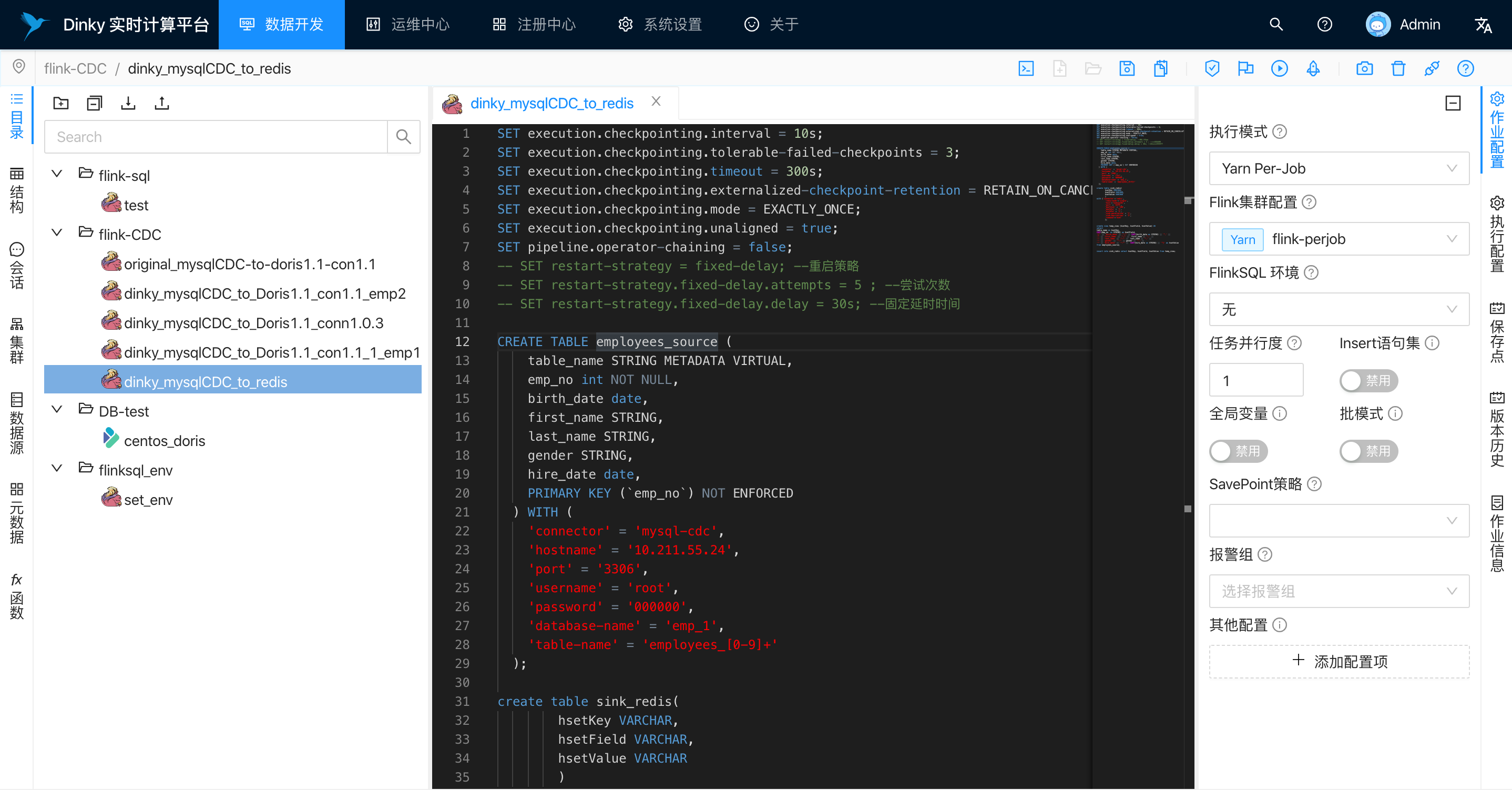
1.2 Flink sql 如下
SET execution.checkpointing.interval = 10s;
SET execution.checkpointing.tolerable-failed-checkpoints = 3;
SET execution.checkpointing.timeout = 300s;
SET execution.checkpointing.externalized-checkpoint-retention = RETAIN_ON_CANCELLATION;
SET execution.checkpointing.mode = EXACTLY_ONCE;
SET execution.checkpointing.unaligned = true;
SET pipeline.operator-chaining = false;
CREATE TABLE employees_source (
table_name STRING METADATA VIRTUAL,
emp_no int NOT NULL,
birth_date date,
first_name STRING,
last_name STRING,
gender STRING,
hire_date date,
PRIMARY KEY (`emp_no`) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = '10.211.55.24',
'port' = '3306',
'username' = 'root',
'password' = '000000',
'database-name' = 'emp_1',
'table-name' = 'employees_[0-9]+'
);
create table sink_redis(
hsetKey VARCHAR,
hsetField VARCHAR,
hsetValue VARCHAR
)
with ('connector'='redis',
'redis-mode'='single',
'host'='hadoop102',
'port' = '6379',
'maxTotal' = '100',
'maxIdle' = '5',
'minIdle' = '5',
'sink.parallelism' = '1',
'sink.max-retries' = '3',
'command'='hset'
);
create view temp_view (hsetKey, hsetField, hsetValue) AS
select
table_name as hsetKey,
CAST(emp_no as STRING) as hsetField,
'{"' || 'birth_date' || '":"' || CAST(birth_date as STRING) || '",' ||
'"' || 'first_name' || '":"' || first_name || '",' ||
'"' || 'last_name' || '":"' || last_name || '",' ||
'"' || 'gender' || '":"' || gender || '",' ||
'"' || 'hire_date' || '":"' || CAST(hire_date as STRING) || '"}' as hsetValue
from employees_source;
insert into sink_redis select hsetKey, hsetField, hsetValue from temp_view;
sql说明:
'{"' || 'birth_date' || '":"' || CAST(birth_date as STRING) || '",' ||
'"' || 'first_name' || '":"' || first_name || '",' ||
'"' || 'last_name' || '":"' || last_name || '",' ||
'"' || 'gender' || '":"' || gender || '",' ||
'"' || 'hire_date' || '":"' || CAST(hire_date as STRING) || '"}' as hsetValue
上面只是把数据库的字段和值, 拼接成json串, 作为redis hset 的value而已, 作为一个案例展示, 没有别的含义.
因flink 1.15版本以上才内置json生成函数, 所以这里用 || 拼接
redis connector 其实支持很多操作, 支持设置更多配置, 更详细的用法还请自行翻阅github.
1.3 运行perjob模式
FlinkWebUI
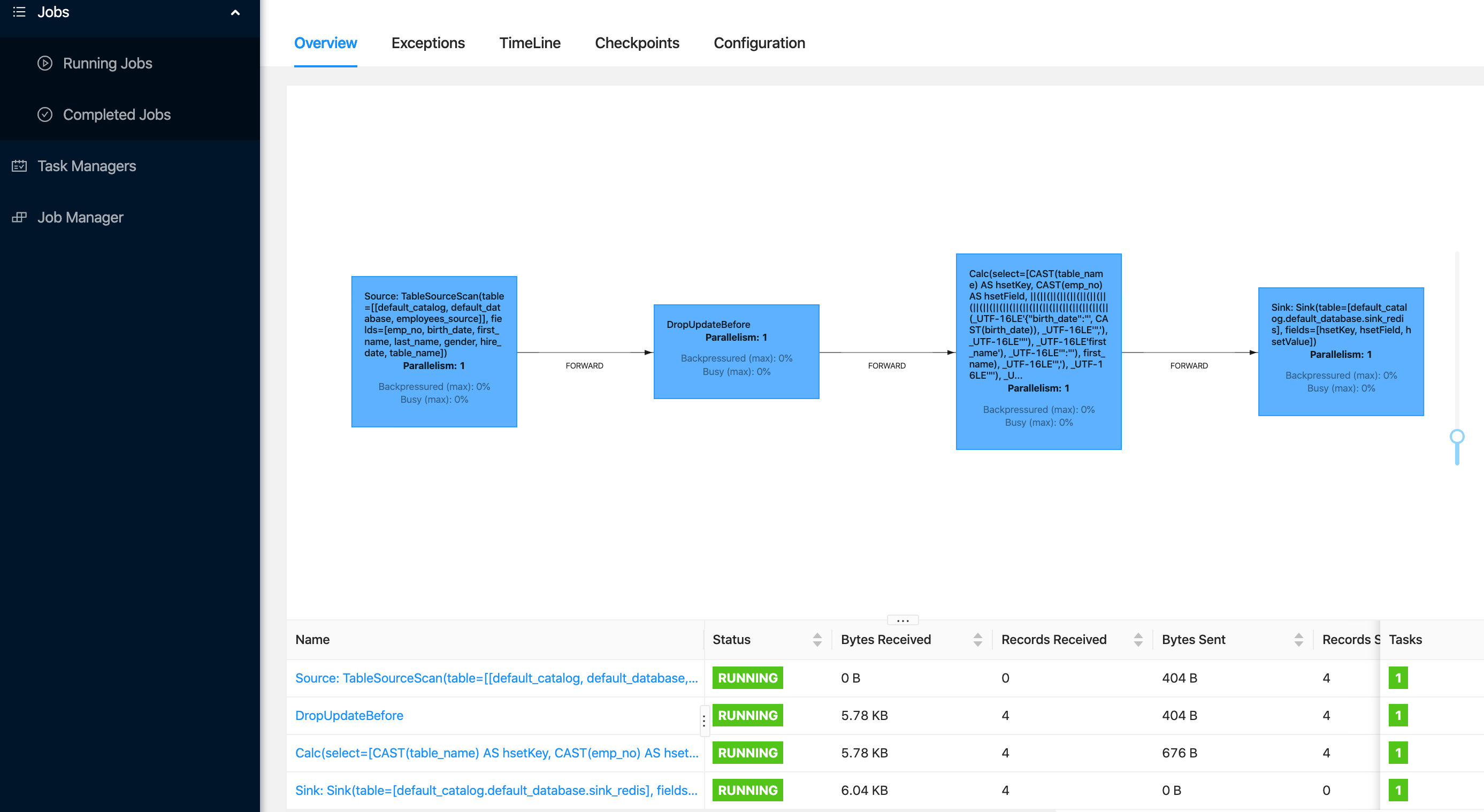
上图可见,流任务已经成功被 Dinky 提交的远程集群了
1.4 数据效果图
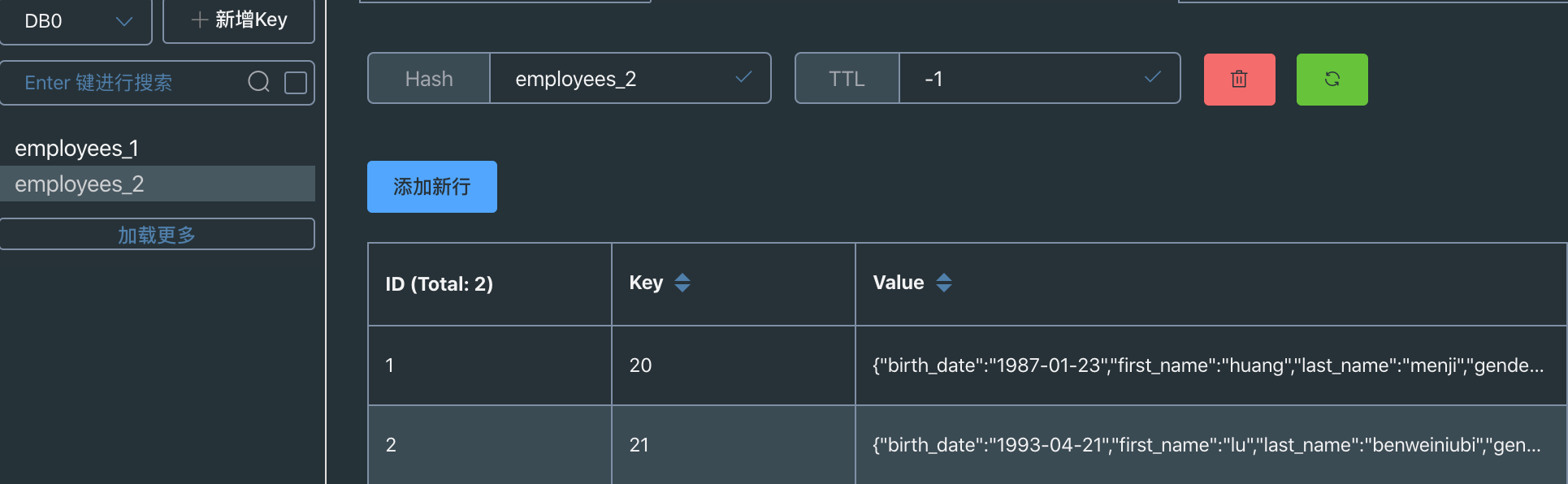

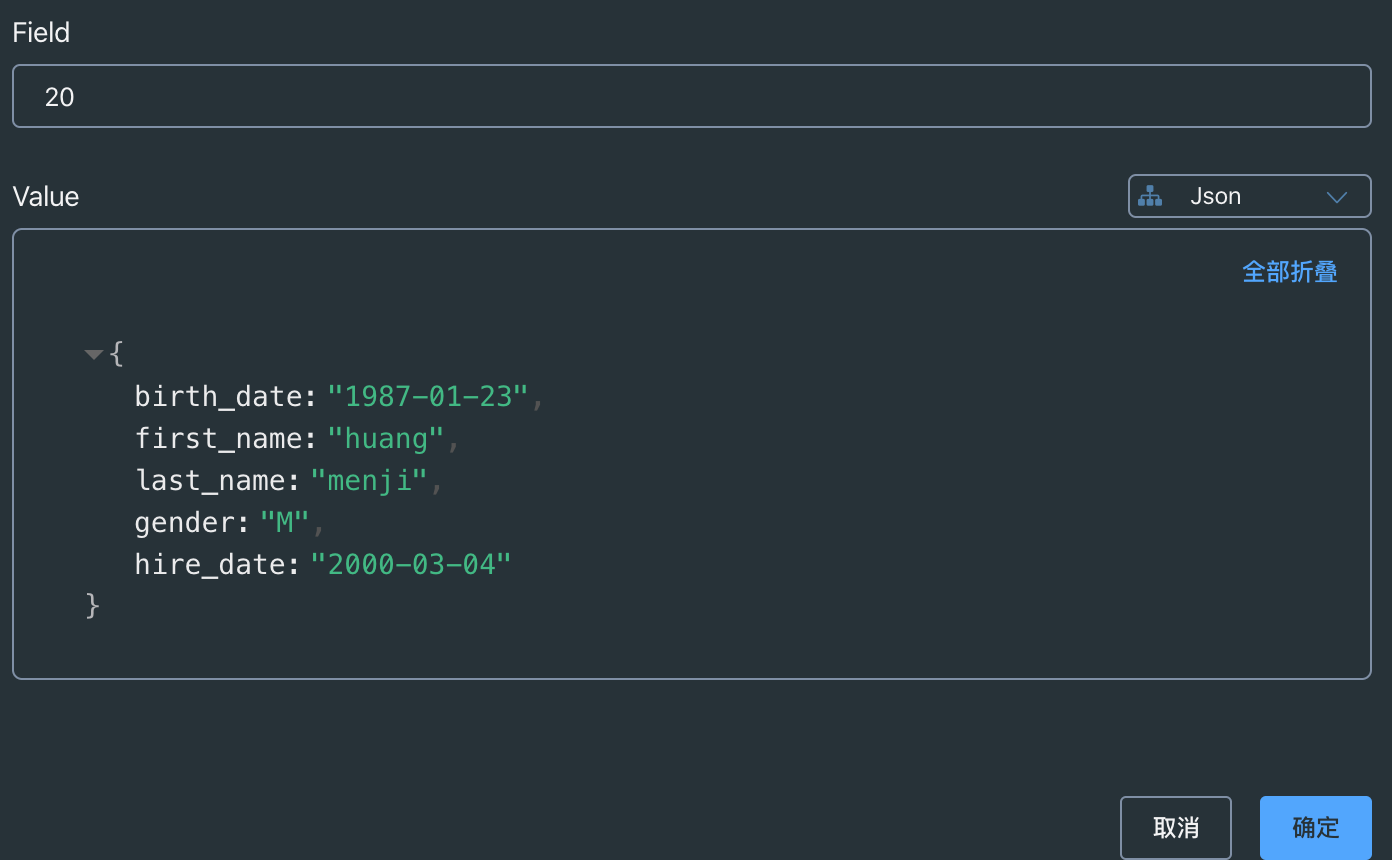
1.5 修改数据
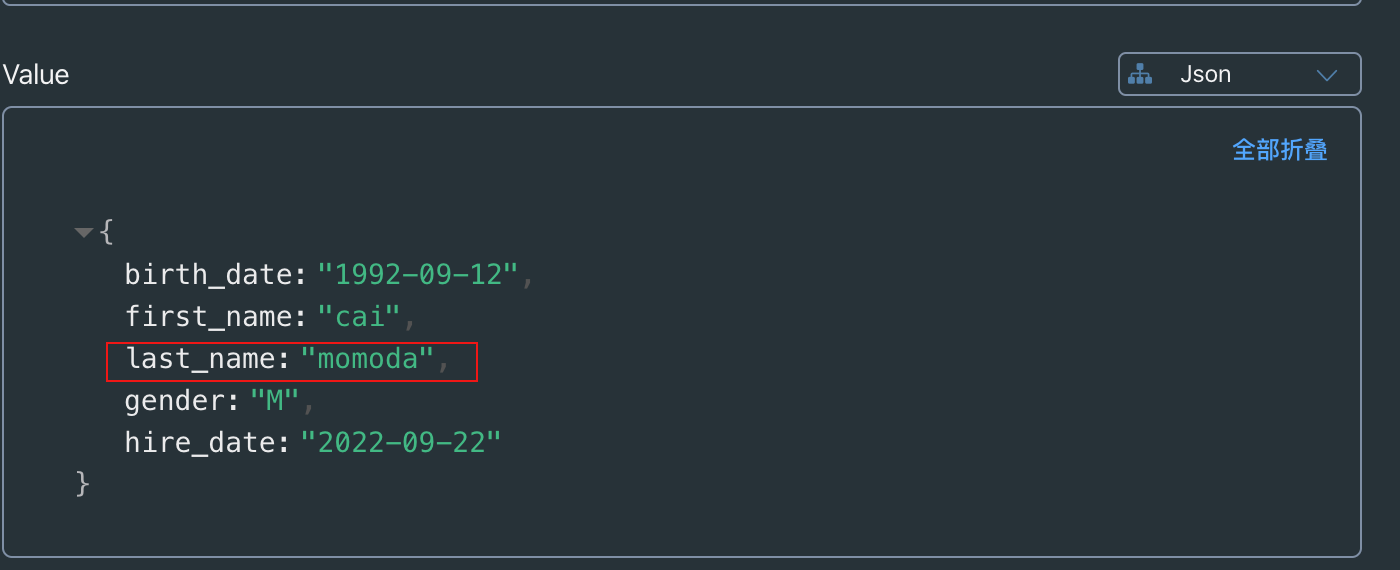
将 last_name 对应的值 kunkun 改为 momoda

flink webui 数据流变化

查看redis数据, 数据已经被修改
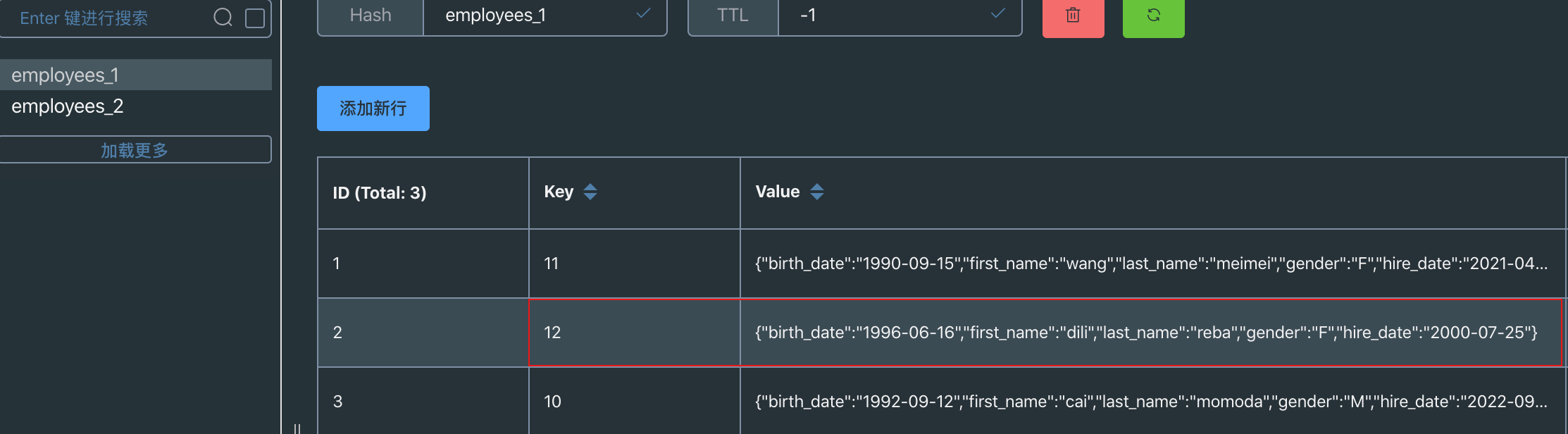
1.6 新增数据
表增加一条数据
insert into employees_1 VALUES ("12", "1996-06-16", "dili", "reba", "F", "2000-07-25");
redis 成功增加一条
场景2
通过flinksql 将kafka 与 redis数据关联
kafka 待发送数据:
{"company_id":"employees_1", "emp_id":"10", "log_id":"log_a_001"}
2.1 Flink sql
SET execution.checkpointing.interval = 10s;
SET execution.checkpointing.tolerable-failed-checkpoints = 3;
SET execution.checkpointing.timeout = 300s;
SET execution.checkpointing.externalized-checkpoint-retention = RETAIN_ON_CANCELLATION;
SET execution.checkpointing.mode = EXACTLY_ONCE;
SET execution.checkpointing.unaligned = true;
SET pipeline.operator-chaining = false;
create table kafka_source(
company_id string,
emp_id string,
log_id string,
event_time as procTime()
) with (
'connector' = 'kafka',
'topic' = 'test',
'properties.bootstrap.servers' = '10.211.55.24:9092',
'properties.group.id' = 'test',
'properties.partition-discovery.interval-millis' = '30000',
'format' = 'json',
'scan.startup.mode' = 'latest-offset'
);
create table dim_redis(
hsetKey VARCHAR,
hsetField VARCHAR,
hsetValue VARCHAR
)
with ('connector'='redis',
'redis-mode'='single',
'host'='hadoop102',
'port' = '6379',
'lookup.cache.max-rows' = '5000',
'lookup.cache.ttl' = '300',
'maxTotal' = '100',
'maxIdle' = '5',
'minIdle' = '5',
'sink.parallelism' = '1',
'sink.max-retries' = '3',
'command'='hget'
);
create table sink_table(
company_id varchar,
emp_id varchar,
log_id varchar,
event_time timestamp,
first_name varchar,
last_name varchar,
hire_date varchar
) with ('connector' = 'print');
create view temp_view as
select
company_id as company_id,
emp_id as emp_id,
log_id as log_id,
event_time as event_time,
JSON_VALUE(d.hsetValue, '$.first_name') as first_name,
JSON_VALUE(d.hsetValue, '$.last_name') as last_name,
JSON_VALUE(d.hsetValue, '$.hire_date') as hire_date
from
kafka_source as k
left join
dim_redis for system_time as of k.event_time as d
on
k.company_id = d.hsetKey
and
k.emp_id = d.hsetField;
insert into sink_table select* from temp_view;
2.2 任务栏

2.3 flink web ui

2.4 成功关联到数据并输出控制台

说明: 参数 pipeline.operator-chaining 是为了临时测试,观看数据流图 业务上不推荐设置为false