Hudi
背景资料
Apache hudi (发音为“ hoodie”)是下一代流式数据湖平台。Apache Hudi 将核心仓库和数据库功能直接引入到数据库中。Hudi 提供表、事务、高效的升级/删除、高级索引、流式摄入服务、数据集群/压缩优化和并发,同时保持数据以开放源码文件格式存储 , Apache Hudi 不仅非常适合流式工作负载,而且它还允许您创建高效的增量批处理管道。
实时数仓流批一体已经成为大势所趋。
为什么要使用 Hudi ?
目前业务架构较为繁重
维护多套框架
数据更新频率较大
准备&&部署
| 组件 | 版本 | 备注 |
|---|---|---|
| Flink | 1.13.5 | 集成到CM |
| Flink-SQL-CDC | 2.1.1 | |
| Hudi | 0.10.0-patch | 打过补丁的 |
| Mysql | 8.0.13 | 阿里云 |
| Dlink | dlink-release-0.5.0-SNAPSHOT.tar.gz | |
| Scala | 2.12 |
1. 部署Flink1.13.5
flink 集成到CM中
此步骤略。
2. 集成Hudi 0.10.0
①. 地址: https://github.com/danny0405/hudi/tree/010-patch 打过补丁的 大佬请忽略^_^
a. 下载压缩包 分支010-patch 不要下载 master 上传 解压
b. unzip 010-patch.zip
c. 找到 packging--hudi-flink-bundle 下的 pom.xml,更改 flink-bundel-shade-hive2 下的 hive-version 更改为 2.1.1-chd6.3.2 的版本。
vim pom.xml # 修改hive版本为 : 2.1.1-cdh6.3.2
d. 执行编译:
mvn clean install -DskipTests -DskipITs -Dcheckstyle.skip=true -Drat.skip=true -Dhadoop.version=3.0.0 -Pflink-bundle-shade-hive2 -Dscala-2.12
因为 chd6.3.0 使用的是 hadoop3.0.0 ,所以要指定 hadoop 的版本, hive 使用的是 2.1.1 的版本,也要指定 hive 的版本,不然使用 sync to hive 的时候,会报类的冲突问题。 scala 版本是 2.12 。
同时 flink 集成到 cm 的时候也是 scala2.12 版本统一。
编译完成如下图:
②. 把相关应的jar包 放到相对应的目录下
# hudi的包
ln -s /opt/module/hudi-0.10.0/hudi-hadoop-mr-bundle/target/hudi-hadoop-mr-bundle-0.10.0.jar /opt/cloudera/parcels/CDH/jars/
ln -s /opt/module/hudi-0.10.0/hudi-hive-sync-bundle/target/hudi-hive-sync-bundle-0.10.0.jar /opt/cloudera/parcels/CDH/jars/
ln -s /opt/module/hudi-0.10.0/hudi-hive-sync-bundle/target/hudi-hive-sync-bundle-0.10.0.jar /opt/cloudera/parcels/CDH/lib/hive/lib
# 同步sync to hive 每台节点都要放
cp /opt/module/hudi-0.10.0/hudi-flink-bundle/target/hudi-flink-bundle_2.12-0.10.0.jar /opt/cloudera/parcels/FLINK/lib/flink/lib/
# 以下三个jar 放到flink/lib 下 否则同步数据到hive的时候会报错
cp /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-client-core-3.0.0-cdh6.3.2.jar /opt/module/flink-1.13.5/lib/
cp /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-client-common-3.0.0-cdh6.3.2.jar /opt/module/flink-1.13.5/lib/
cp /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-client-jobclient-3.0.0-cdh6.3.2.jar /opt/module/flink-1.13.5/lib/
# 执行以下命令
cd /opt/module/flink-1.13.5/lib/
scp -r ./* cdh5:`pwd`
scp -r ./* cdh6:`pwd`
scp -r ./* cdh7:`pwd`
3. 安装 Dlink-0.5.0
a. github 地址: https://github.com/DataLinkDC/dlink
b. 部署步骤见 github-readme.md 传送门: https://github.com/DataLinkDC/dlink/blob/main/README.md
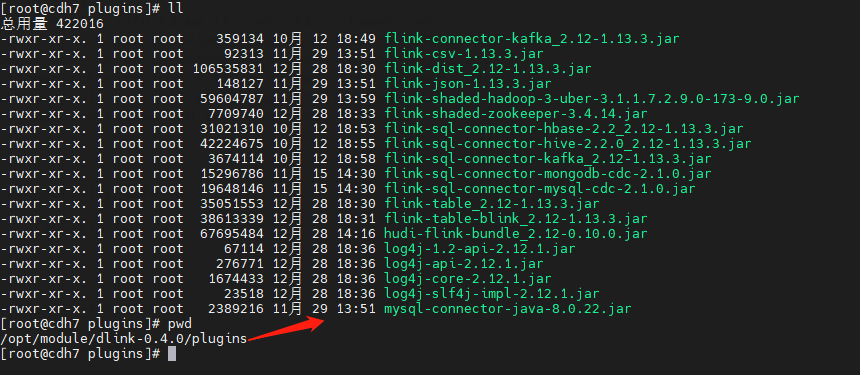
ps: 注意 还需要将 hudi-flink-bundle_2.12-0.10.0.jar 这个包放到 dlink的 plugins 下 。
plugins 下的包 如下图所示:
c. 访问: http://ip:port/#/user/login 默认用户: admin 密码: admin
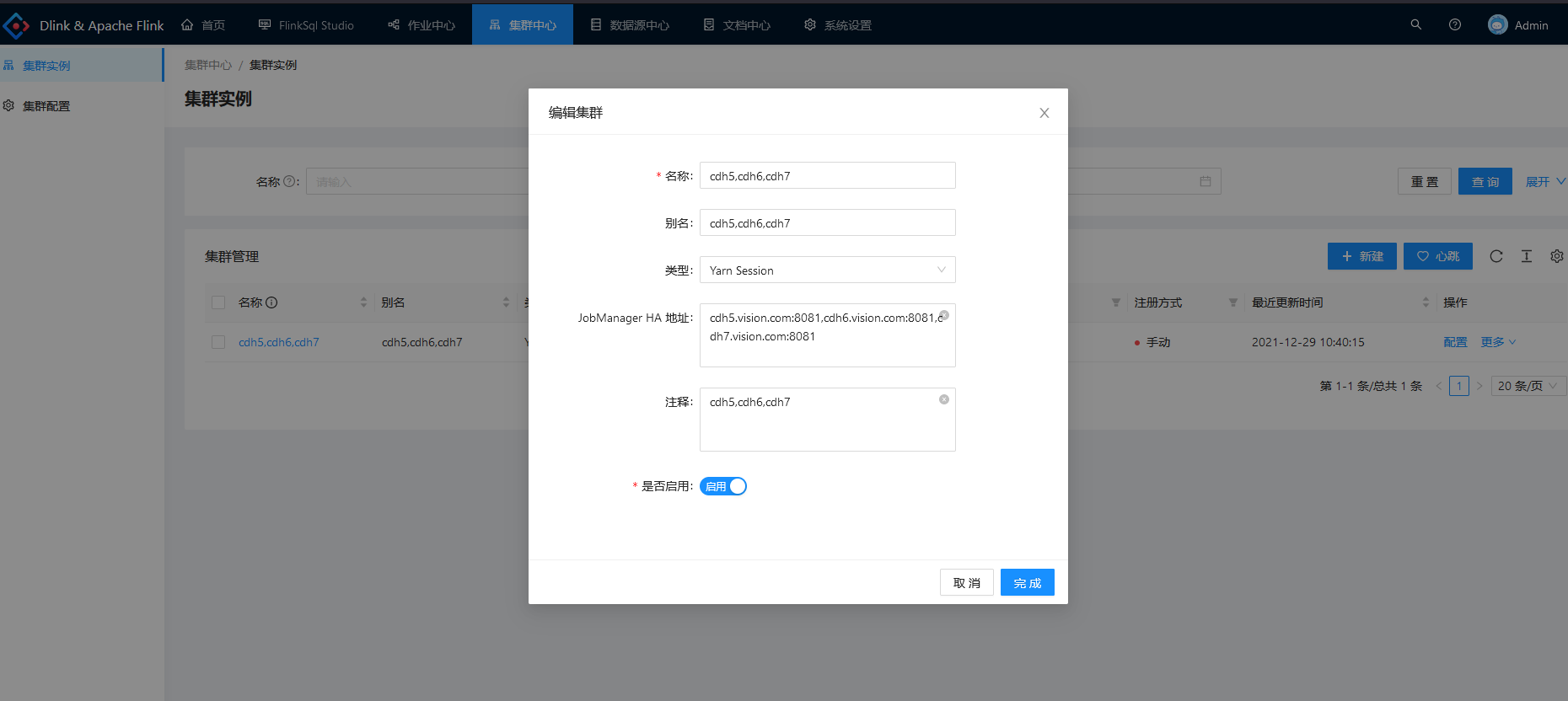
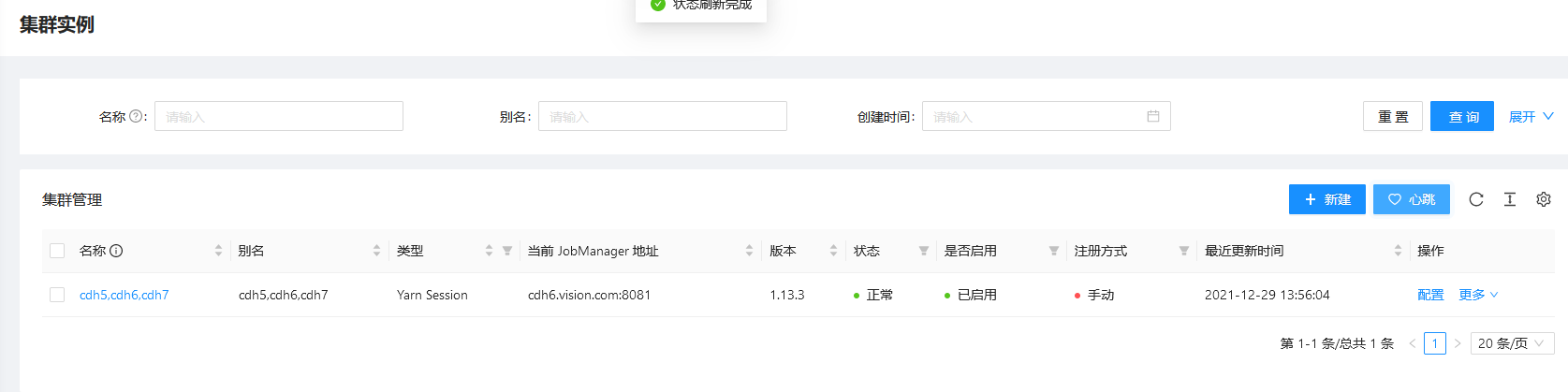
d. 创建集群实例:
数据表
1. DDL准备
(以下ddl 通过Python程序模板生成 大佬请略过! O(∩_∩)O )
------------- '订单表' order_mysql_goods_order -----------------
CREATE TABLE source_order_mysql_goods_order (
`goods_order_id` bigint COMMENT '自增主键id'
, `goods_order_uid` string COMMENT '订单uid'
, `customer_uid` string COMMENT '客户uid'
, `customer_name` string COMMENT '客户name'
, `student_uid` string COMMENT '学生uid'
, `order_status` bigint COMMENT '订单状态 1:待付款 2:部分付款 3:付款审核 4:已付款 5:已取消'
, `is_end` bigint COMMENT '订单是否完结 1.未完结 2.已完结'
, `discount_deduction` bigint COMMENT '优惠总金额(单位:分)'
, `contract_deduction` bigint COMMENT '老合同抵扣金额(单位:分)'
, `wallet_deduction` bigint COMMENT '钱包抵扣金额(单位:分)'
, `original_price` bigint COMMENT '订单原价(单位:分)'
, `real_price` bigint COMMENT '实付金额(单位:分)'
, `pay_success_time` timestamp(3) COMMENT '完全支付时间'
, `tags` string COMMENT '订单标签(1新签 2续费 3扩科 4报名-合新 5转班-合新 6续费-合新 7试听-合新)'
, `status` bigint COMMENT '是否有效(1.生效 2.失效 3.超时未付款)'
, `remark` string COMMENT '订单备注'
, `delete_flag` bigint COMMENT '是否删除(1.否,2.是)'
, `test_flag` bigint COMMENT '是否测试数据(1.否,2.是)'
, `create_time` timestamp(3) COMMENT '创建时间'
, `update_time` timestamp(3) COMMENT '更新时间'
, `create_by` string COMMENT '创建人uid(唯一标识)'
, `update_by` string COMMENT '更新人uid(唯一标识)'
,PRIMARY KEY(goods_order_id) NOT ENFORCED
) COMMENT '订单表'
WITH (
'connector' = 'mysql-cdc'
,'hostname' = 'rm-bp1t34384933232rds.aliyuncs.com'
,'port' = '3306'
,'username' = 'app_kfkdr'
,'password' = 'CV122fff0E40'
,'server-time-zone' = 'UTC'
,'scan.incremental.snapshot.enabled' = 'true'
,'debezium.snapshot.mode'='latest-offset' -- 或者key是scan.startup.mode,initial表示要历史数据,latest-offset表示不要历史数据
,'debezium.datetime.format.date'='yyyy-MM-dd'
,'debezium.datetime.format.time'='HH-mm-ss'
,'debezium.datetime.format.datetime'='yyyy-MM-dd HH-mm-ss'
,'debezium.datetime.format.timestamp'='yyyy-MM-dd HH-mm-ss'
,'debezium.datetime.format.timestamp.zone'='UTC+8'
,'database-name' = 'order'
,'table-name' = 'goods_order'
-- ,'server-id' = '2675788754-2675788754'
);
CREATE TABLE sink_order_mysql_goods_order(
`goods_order_id` bigint COMMENT '自增主键id'
, `goods_order_uid` string COMMENT '订单uid'
, `customer_uid` string COMMENT '客户uid'
, `customer_name` string COMMENT '客户name'
, `student_uid` string COMMENT '学生uid'
, `order_status` bigint COMMENT '订单状态 1:待付款 2:部分付款 3:付款审核 4:已付款 5:已取消'
, `is_end` bigint COMMENT '订单是否完结 1.未完结 2.已完结'
, `discount_deduction` bigint COMMENT '优惠总金额(单位:分)'
, `contract_deduction` bigint COMMENT '老合同抵扣金额(单位:分)'
, `wallet_deduction` bigint COMMENT '钱包抵扣金额(单位:分)'
, `original_price` bigint COMMENT '订单原价(单位:分)'
, `real_price` bigint COMMENT '实付金额(单位:分)'
, `pay_success_time` timestamp(3) COMMENT '完全支付时间'
, `tags` string COMMENT '订单标签(1新签 2续费 3扩科 4报名-合新 5转班-合新 6续费-合新 7试听-合新)'
, `status` bigint COMMENT '是否有效(1.生效 2.失效 3.超时未付款)'
, `remark` string COMMENT '订单备注'
, `delete_flag` bigint COMMENT '是否删除(1.否,2.是)'
, `test_flag` bigint COMMENT '是否测试数据(1.否,2.是)'
, `create_time` timestamp(3) COMMENT '创建时间'
, `update_time` timestamp(3) COMMENT '更新时间'
, `create_by` string COMMENT '创建人uid(唯一标识)'
, `update_by` string COMMENT '更新人uid(唯一标识)'
,PRIMARY KEY (goods_order_id) NOT ENFORCED
) COMMENT '订单表'
WITH (
'connector' = 'hudi'
, 'path' = 'hdfs://cluster1/data/bizdata/cdc/mysql/order/goods_order' -- 路径会自动创建
, 'hoodie.datasource.write.recordkey.field' = 'goods_order_id' -- 主键
, 'write.precombine.field' = 'update_time' -- 相同的键值时,取此字段最大值,默认ts字段
, 'read.streaming.skip_compaction' = 'true' -- 避免重复消费问题
, 'write.bucket_assign.tasks' = '2' -- 并发写的 bucekt 数
, 'write.tasks' = '2'
, 'compaction.tasks' = '1'
, 'write.operation' = 'upsert' -- UPSERT(插入更新)\INSERT(插入)\BULK_INSERT(批插入)(upsert性能会低些,不适合埋点上报)
, 'write.rate.limit' = '20000' -- 限制每秒多少条
, 'table.type' = 'COPY_ON_WRITE' -- 默认COPY_ON_WRITE ,
, 'compaction.async.enabled' = 'true' -- 在线压缩
, 'compaction.trigger.strategy' = 'num_or_time' -- 按次数压缩
, 'compaction.delta_commits' = '20' -- 默认为5
, 'compaction.delta_seconds' = '60' -- 默认为1小时
, 'hive_sync.enable' = 'true' -- 启用hive同步
, 'hive_sync.mode' = 'hms' -- 启用hive hms同步,默认jdbc
, 'hive_sync.metastore.uris' = 'thrift://cdh2.vision.com:9083' -- required, metastore的端口
, 'hive_sync.jdbc_url' = 'jdbc:hive2://cdh1.vision.com:10000' -- required, hiveServer地址
, 'hive_sync.table' = 'order_mysql_goods_order' -- required, hive 新建的表名 会自动同步hudi的表结构和数据到hive
, 'hive_sync.db' = 'cdc_ods' -- required, hive 新建的数据库名
, 'hive_sync.username' = 'hive' -- required, HMS 用户名
, 'hive_sync.password' = '123456' -- required, HMS 密码
, 'hive_sync.skip_ro_suffix' = 'true' -- 去除ro后缀
);
---------- source_order_mysql_goods_order=== TO ==>> sink_order_mysql_goods_order ------------
insert into sink_order_mysql_goods_order select * from source_order_mysql_goods_order;
调试
1.对上述SQL执行语法校验:
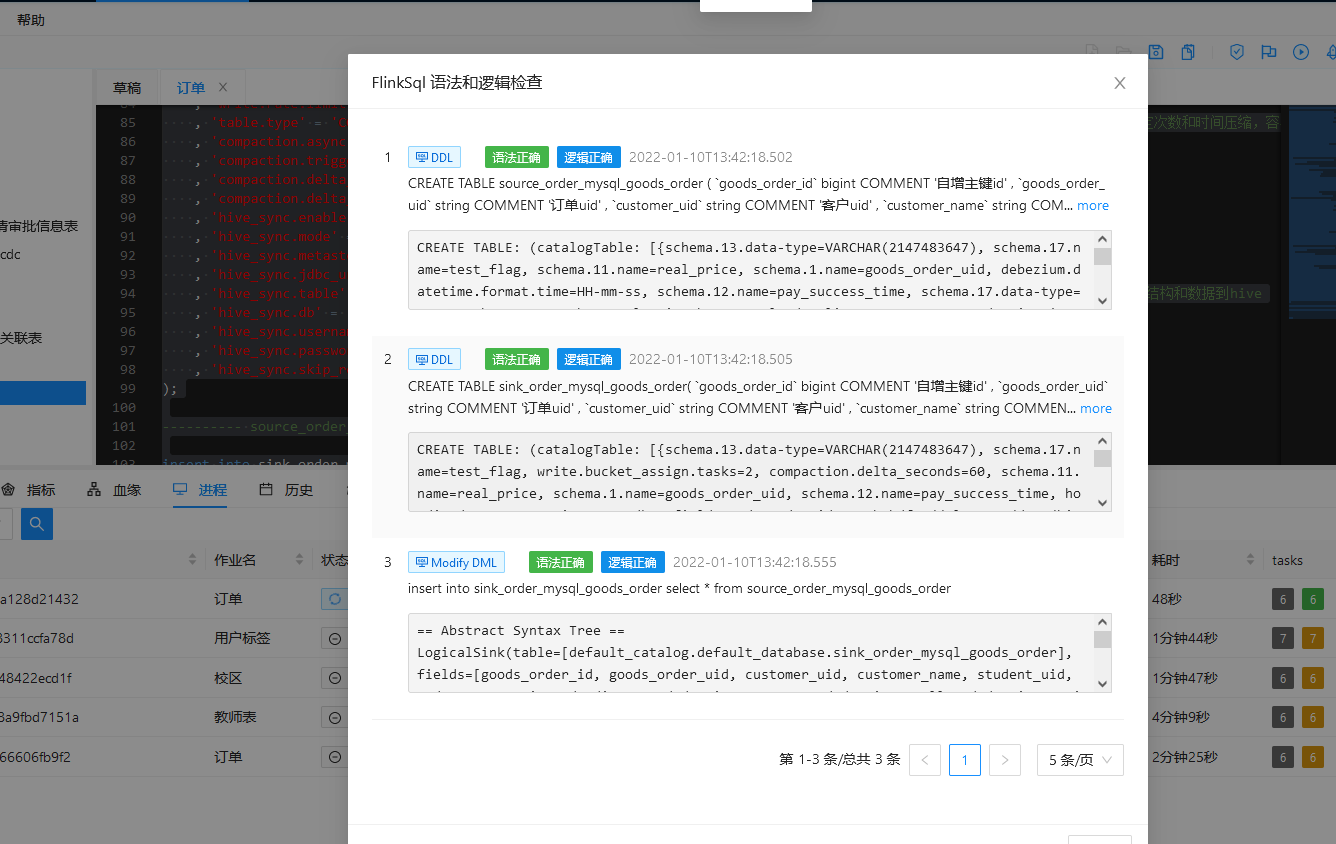
2. 获取JobPlan
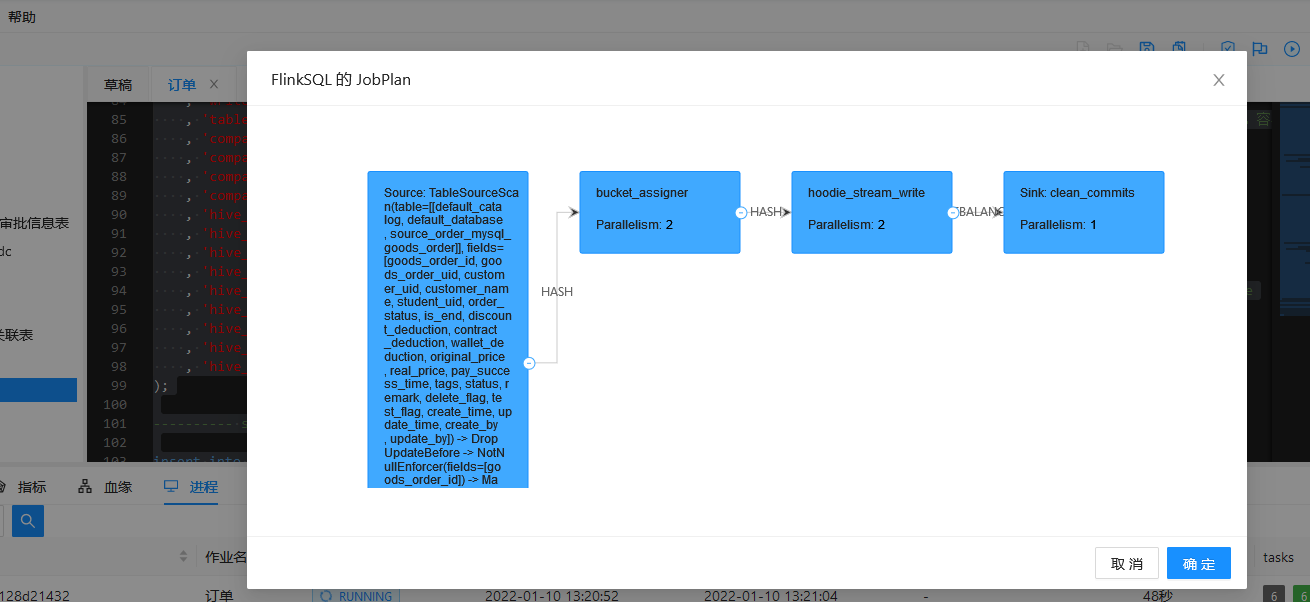
3. 执行任务
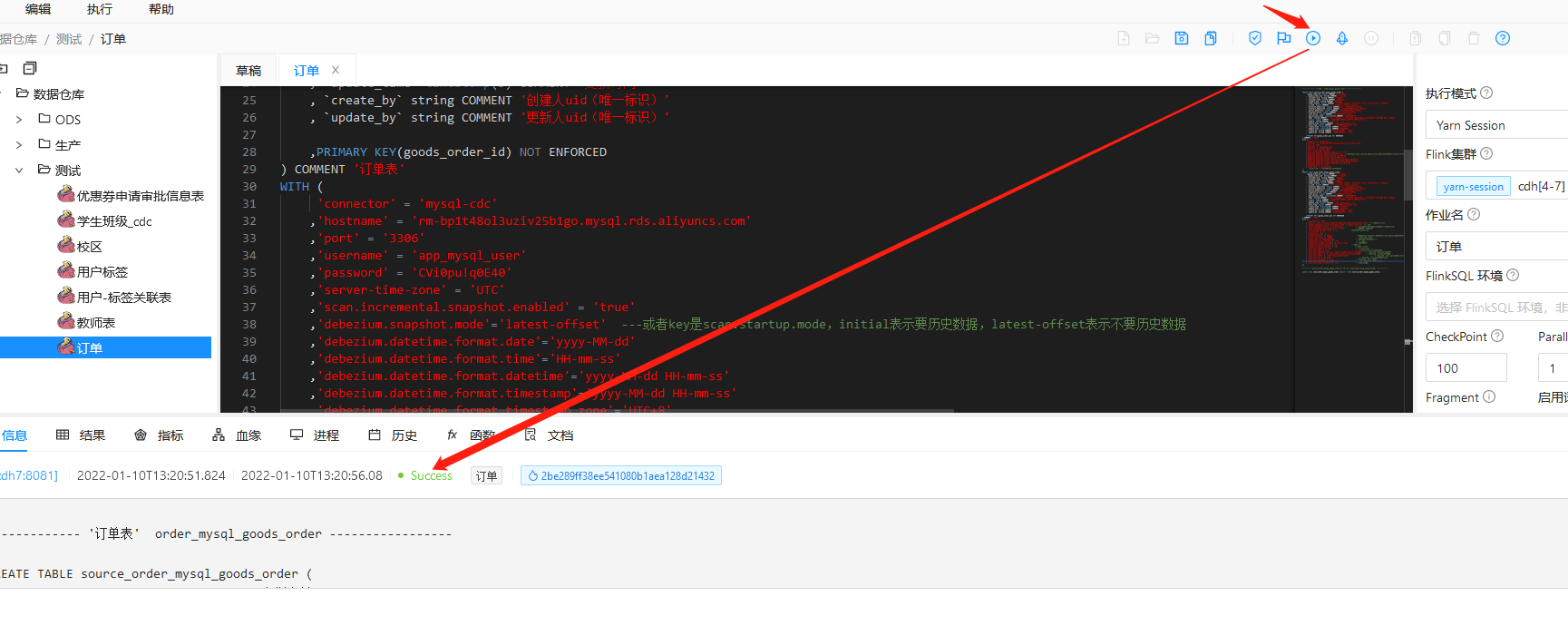
4. dlink 查看执行的任务
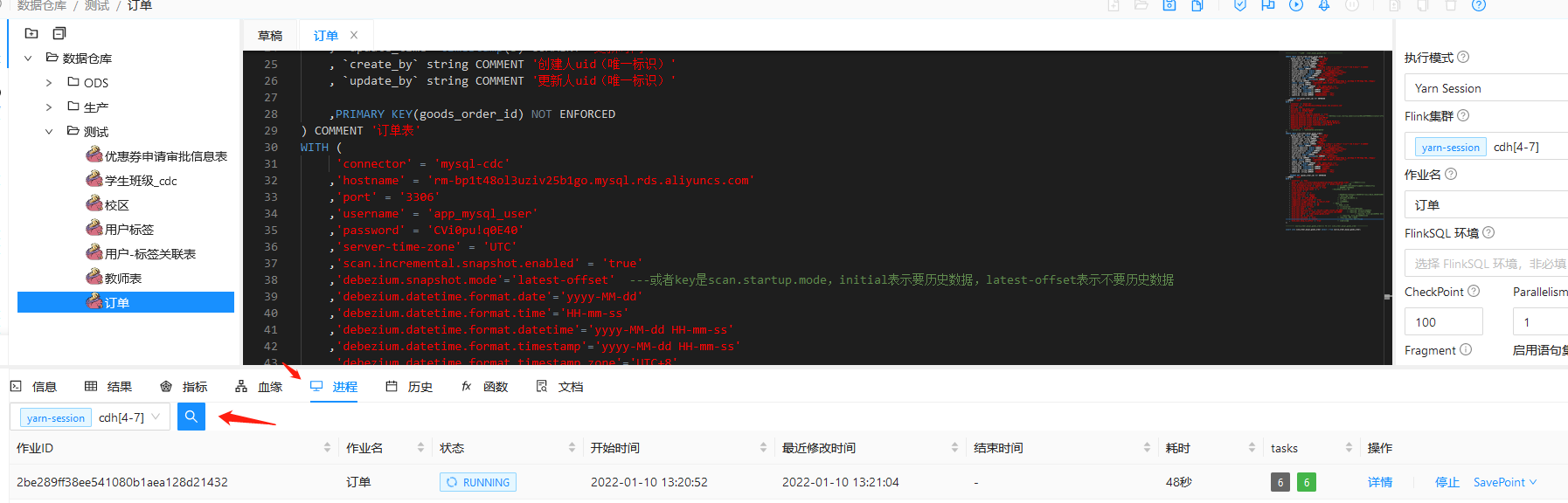
5. Flink-webUI 查看 作业
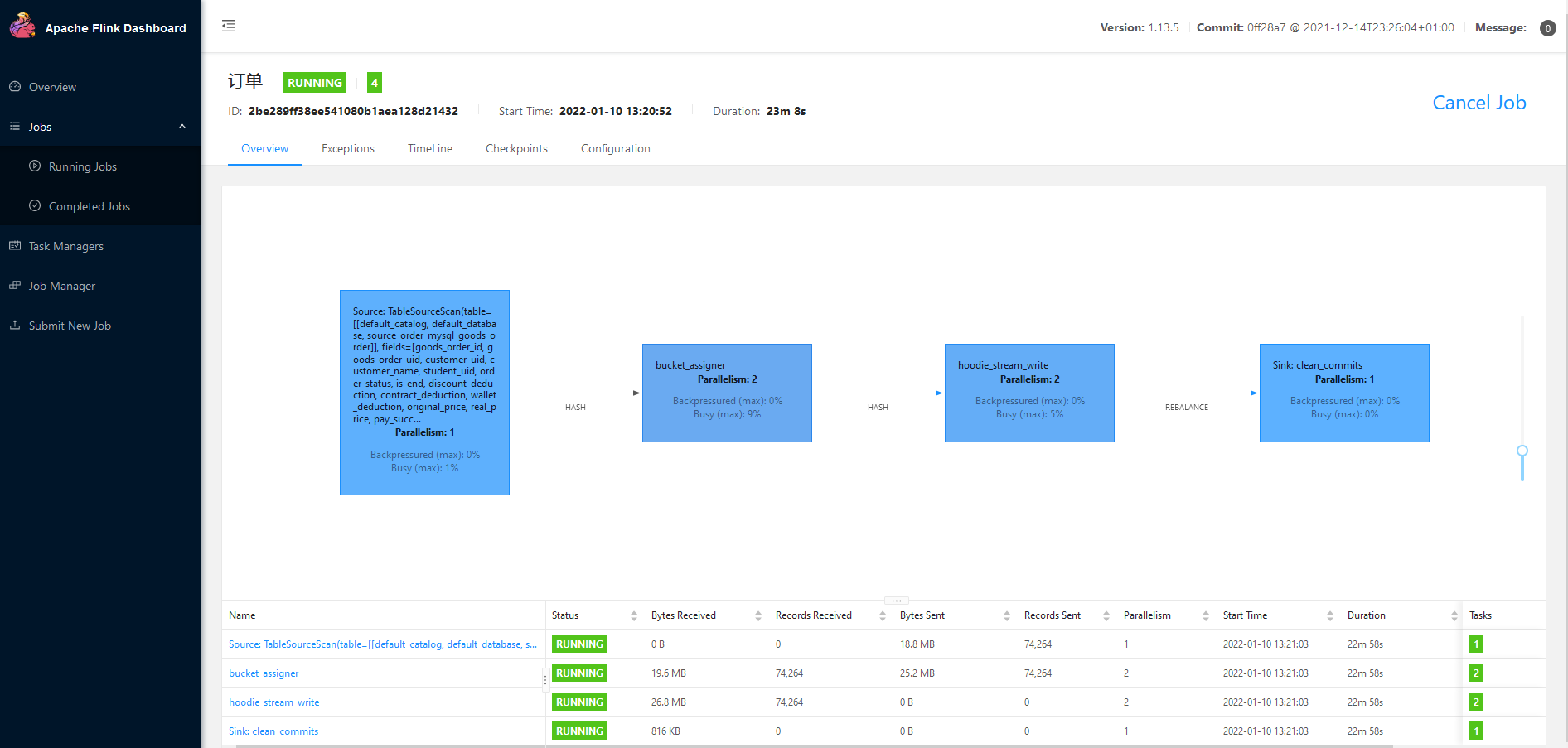
6. 查看hdfs路径下数据
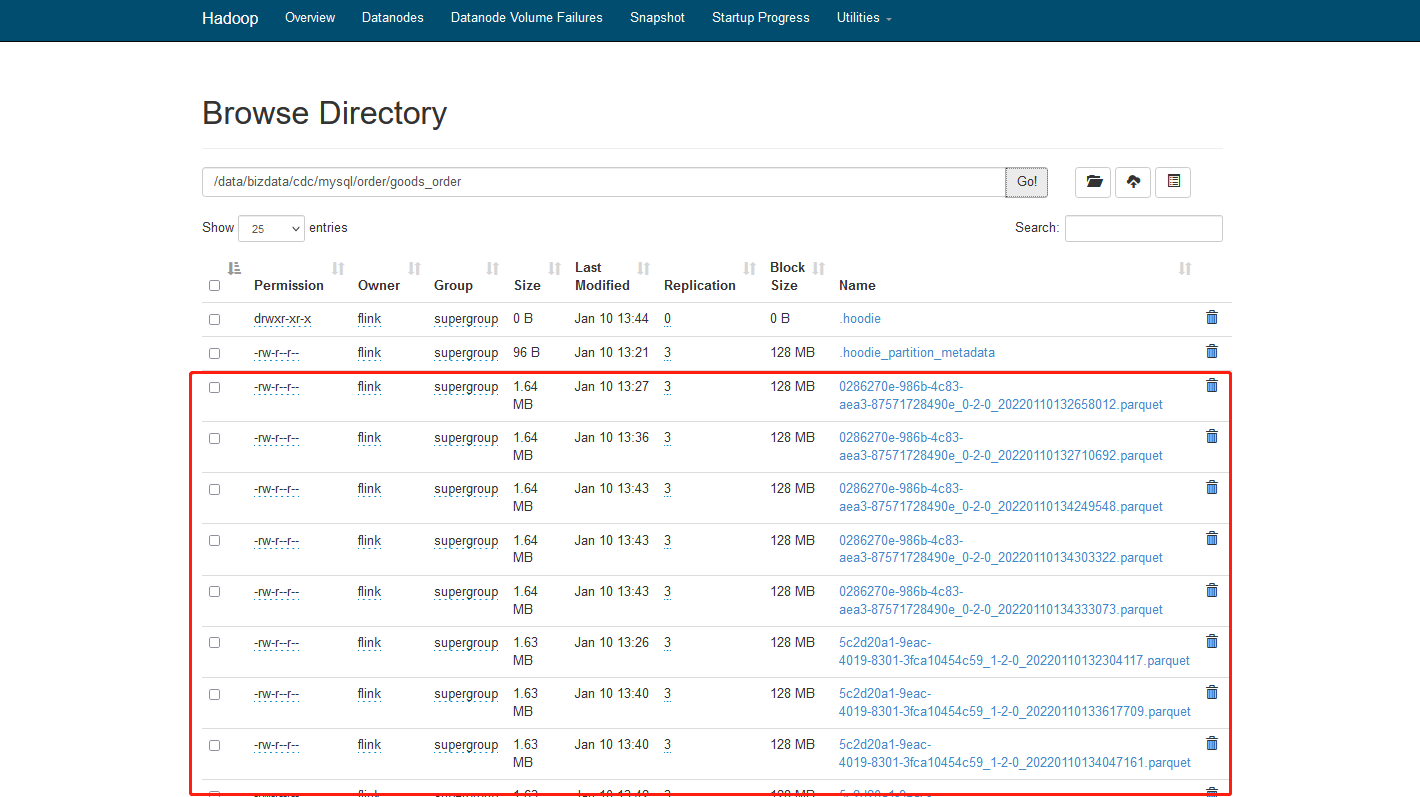
7. 查看hive表:

查看订单号对应的数据
8.更新数据操作
UPDATE `order`.`goods_order`
SET
`remark` = 'cdc_test update'
WHERE
`goods_order_id` = 73270;
再次查看 hive 数据 发现已经更新
9.删除数据操作
(内部业务中采用逻辑删除 不使用物理删除 此例仅演示/测试使用 谨慎操作)
delete from `order`.`goods_order` where goods_order_id='73270';
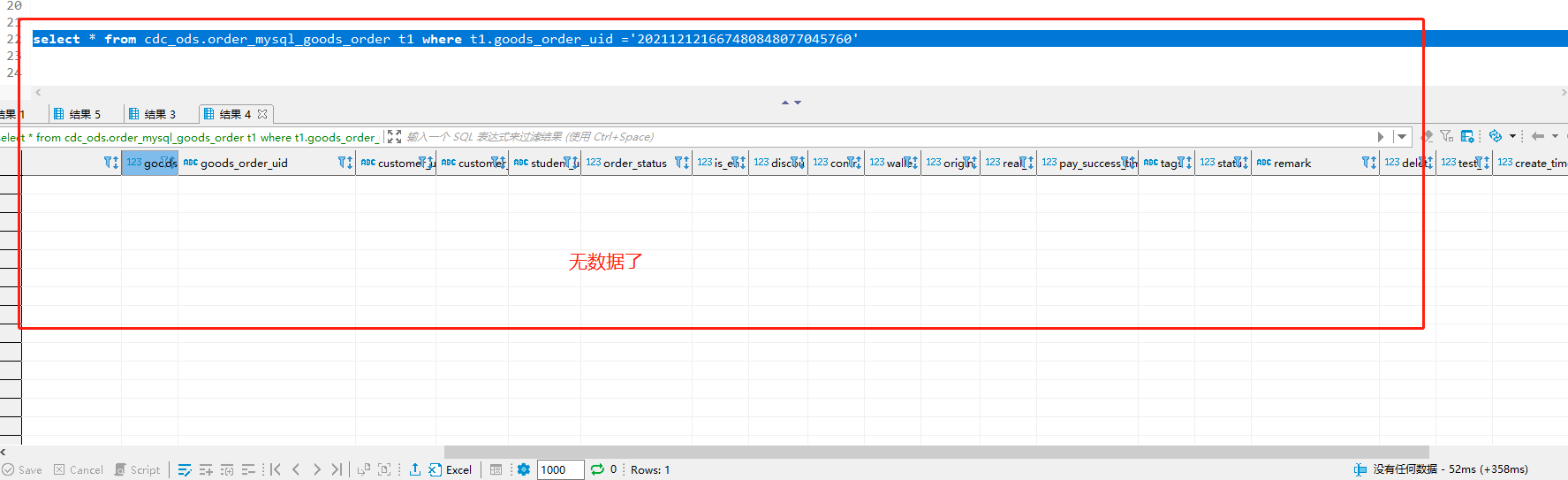
10.将此数据再次插入
INSERT INTO `order`.`goods_order`(`goods_order_id`, `goods_order_uid`, `customer_uid`, `customer_name`, `student_uid`, `order_status`, `is_end`, `discount_deduction`, `contract_deduction`, `wallet_deduction`, `original_price`, `real_price`, `pay_success_time`, `tags`, `status`, `remark`, `delete_flag`, `test_flag`, `create_time`, `update_time`, `create_by`, `update_by`) VALUES (73270, '202112121667480848077045760', 'VA100002435', 'weweweywu', 'S100002435', 4, 1, 2000000, 0, 0, 2000000, 0, '2021-12-12 18:51:41', '1', 1, '', 1, 1, '2021-12-12 18:51:41', '2022-01-10 13:53:59', 'VA100681', 'VA100681');
再次查询hive数据 数据正常进入。

至此 Dlink在Flink-SQL-CDC 到Hudi Sync Hive 测试结束
结论
通过 Dlink + Flink-Mysql-CDC + Hudi 的方式大大降低了我们流式入湖的成本,其中 Flink-Mysql-CDC 简化了CDC的架构与成本,而 Hudi 高性能的读写更有利于变动数据的存储,最后 Dlink 则将整个数据开发过程 sql 平台化,使我们的开发运维更加专业且舒适,期待 Dlink 后续的发展。
作者
zhumingye