Kudu
编辑: roohom
说在前面
下面介绍如何通过Dinky整合Kudu,以支持写SQL来实现数据的读取或写入Kudu。
Flink官网介绍了如何去自定义一个支持Source或者Sink的Connector,这不是本文探讨的重点,本文侧重于用别人已经写好的Connector去与Dinky做集成以支持读写Kudu。
注意:以下内容基于Flink1.13.6 Dinky0.6.2,当然其他版本同理。
准备工作
在Kudu上创建一个表,这里为test

我们还需要一个Flink可以使用的针对kudu的Connector,我们找到[flink-connector-kudu]这个项目,clone该项目并在本地适当根据本地所使用组件的版本修改代码进行编译。
1、修改pom
<flink.version>1.13.6</flink.version>
<kudu.version>1.14.0</kudu.version>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.2.4</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
这里将Flink版本修改为1.13.6, 并且使用1.14.0版本的kudu-client,因为项目作者在README中已经说明了使用1.10.0会存在问题,并且添加了shade方式打包
2、修改org.colloh.flink.kudu.connector.table.catalog.KuduCatalogFactory
构建及使用
1、OK,准备工作完毕,我们将项目编译打包(步骤略),将得到的jar放在flink的lib目录下以及dinky的plugins目录下,如果需要使用yarn-application模式提交任务,还需要将jar放在HDFS上合适位置让flink能访问到。
2、OK,重启Dinky,如果使用yarn-session模式,咱们需要重启得到一个session集群,进入dinky的注册中心配置一个合适的集群实例

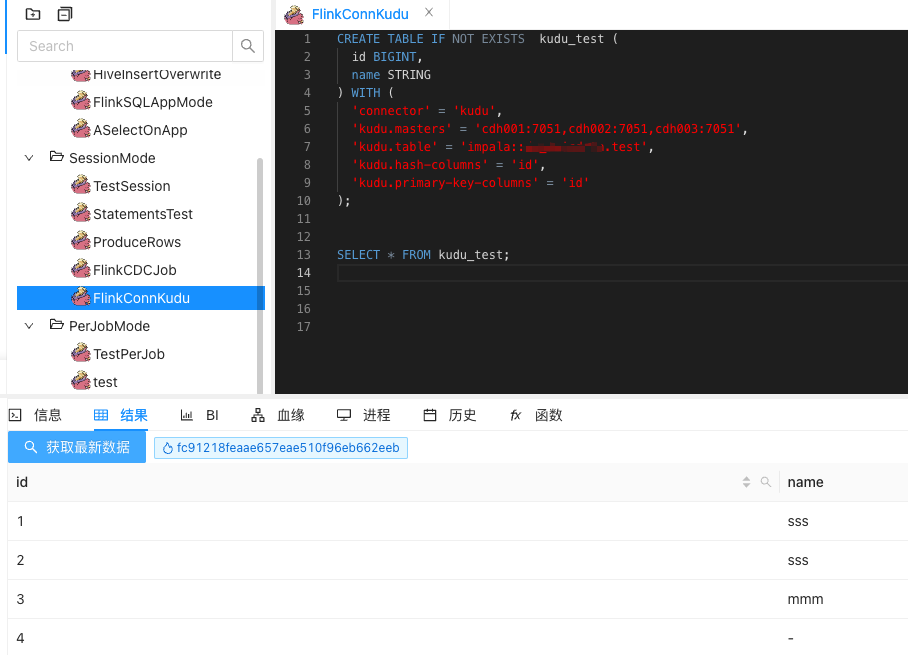
3、接下来我们去dinky的数据开发界面,写一个读取的SQL demo
CREATE TABLE IF NOT EXISTS kudu_test (
id BIGINT,
name STRING
) WITH (
'connector' = 'kudu',
'kudu.masters' = 'cdh001:7051,cdh002:7051,cdh003:7051',
'kudu.table' = 'impala::xxx.test',
'kudu.hash-columns' = 'id',
'kudu.primary-key-columns' = 'id'
);
SELECT * FROM kudu_test;
点击运行
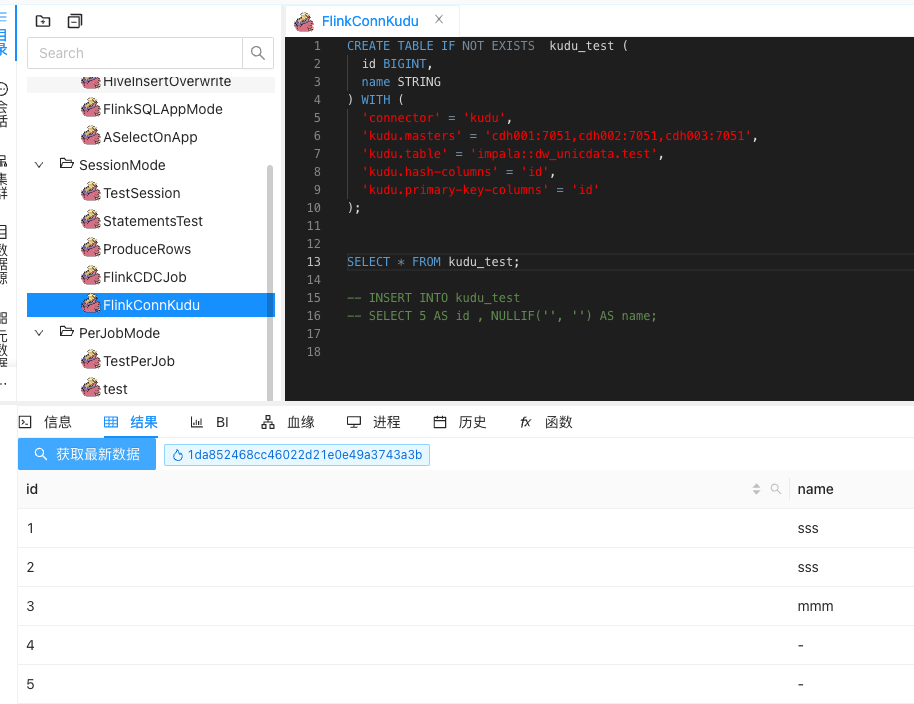
4、再来一个写入数据的SQL demo
CREATE TABLE IF NOT EXISTS kudu_test (
id BIGINT,
name STRING
) WITH (
'connector' = 'kudu',
'kudu.masters' = 'cdh001:7051,cdh002:7051,cdh003:7051',
'kudu.table' = 'impala::xxx.test',
'kudu.hash-columns' = 'id',
'kudu.primary-key-columns' = 'id'
);
INSERT INTO kudu_test
SELECT 5 AS id , NULLIF('', '') AS name;

成功运行,再去查看kudu表的数据
集成完毕。