kafka写入hive
写入无分区表
下面的案例演示的是将 kafka 表中的数据,经过处理之后,直接写入 hive 无分区表,具体 hive 表中的数据什么时候可见,具体请查看 insert 语句中对 hive 表使用的 sql 提示。
hive 表
CREATE TABLE `test.order_info`(
`id` int COMMENT '订单id',
`product_count` int COMMENT '购买商品数量',
`one_price` double COMMENT '单个商品价格')
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://hadoopCluster/user/hive/warehouse/test.db/order_info'
TBLPROPERTIES (
'transient_lastDdlTime'='1659250044')
;
flink sql 语句
-- 如果是 flink-1.13.x ,则需要手动设置该参数
set 'table.dynamic-table-options.enabled' = 'true';
-- 在需要读取hive或者是写入hive表时,必须创建hive catalog。
-- 创建catalog
create catalog hive with (
'type' = 'hive',
'hadoop-conf-dir' = '/data/soft/dlink-0.6.6/hadoop-conf',
'hive-conf-dir' = '/data/soft/dlink-0.6.6/hadoop-conf'
)
;
use catalog hive;
-- 创建连接 kafka 的虚拟表作为 source,此处使用 temporary ,是为了不让创建的虚拟表元数据保存到 hive,可以让任务重启是不出错。
-- 如果想让虚拟表元数据保存到 hive ,则可以在创建语句中加入 if not exist 语句。
CREATE temporary TABLE source_kafka(
id integer comment '订单id',
product_count integer comment '购买商品数量',
one_price double comment '单个商品价格'
) WITH (
'connector' = 'kafka',
'topic' = 'data_gen_source',
'properties.bootstrap.servers' = 'node01:9092,node02:9092,node03:9092',
'properties.group.id' = 'for_source_test',
'scan.startup.mode' = 'latest-offset',
'format' = 'csv',
'csv.field-delimiter' = ' '
)
;
insert into test.order_info
-- 下面的语法是 flink sql 提示,用于在语句中使用到表时手动设置一些临时的参数
/*+
OPTIONS(
-- 设置写入的文件滚动时间间隔
'sink.rolling-policy.rollover-interval' = '10 s',
-- 设置检查文件是否需要滚动的时间间隔
'sink.rolling-policy.check-interval' = '1 s',
-- sink 并行度
'sink.parallelism' = '1'
)
*/
select id, product_count, one_price
from source_kafka
;
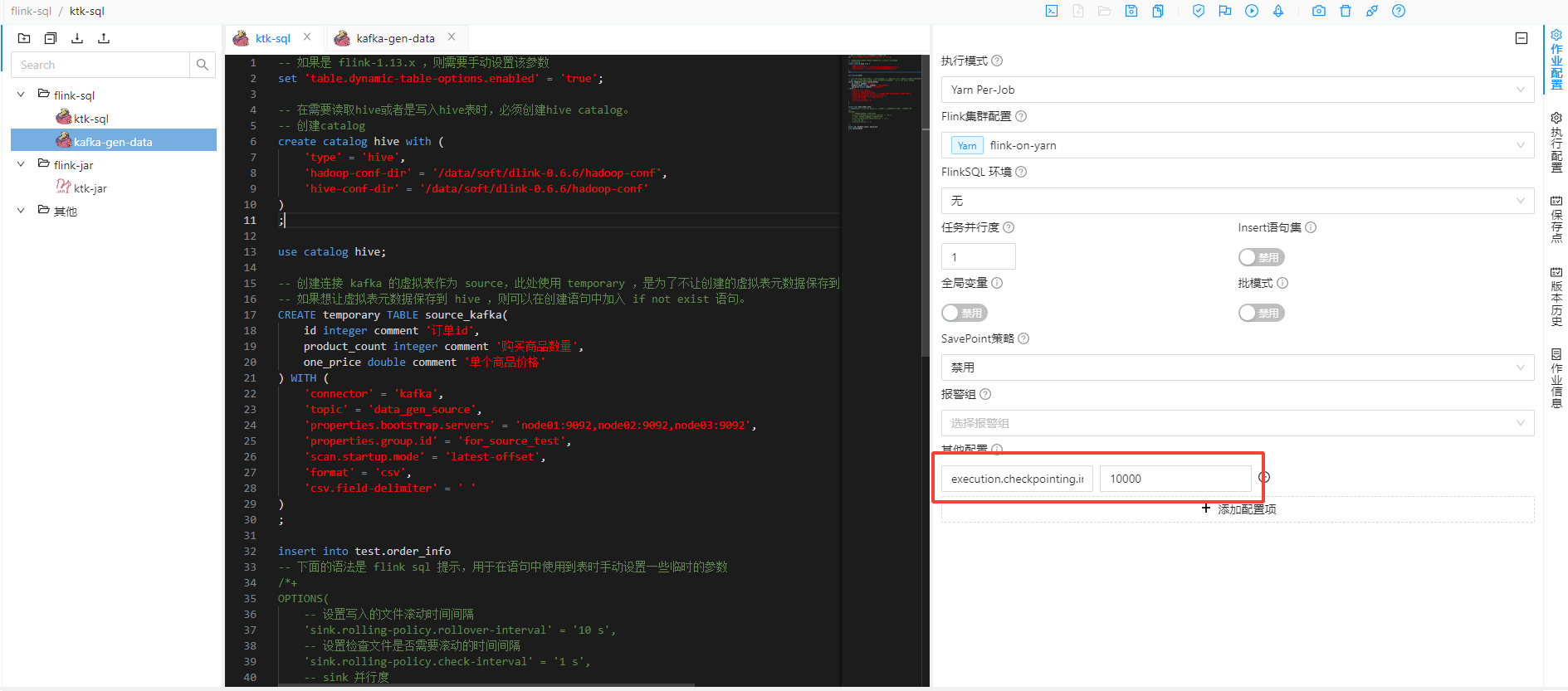
flink sql 写入 hive ,依赖的是 fileSystem 连接器,该连接器写入到文件系统的文件可见性,依赖于 flink 任务的 checkpoint ,
所以 dlink 界面提交任务时,一定要开启 checkpoint ,也就是设置 checkpoint 的时间间隔参数 execution.checkpointing.interval ,如下图所示,设置为 10000 毫秒。
任务运行之后,就可以看到如下的 fink ui 界面了
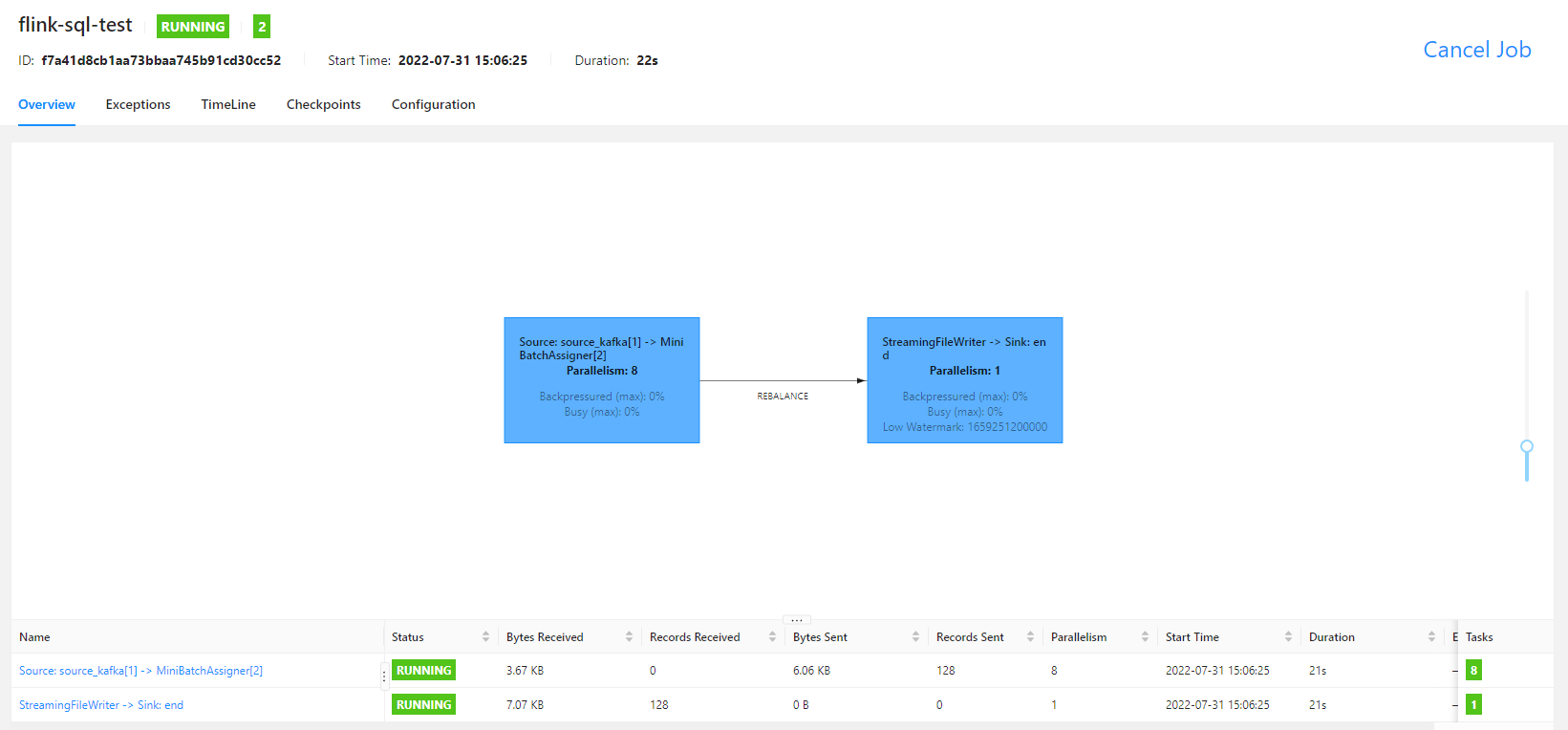
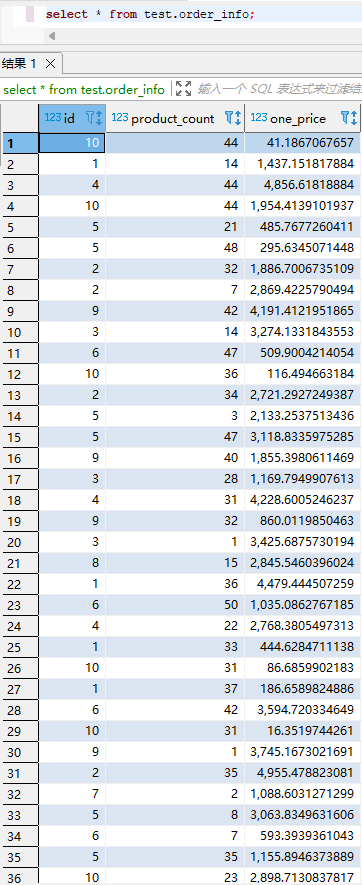
本案例使用 streaming 方式运行, checkpoint 时间为 10 s,文件滚动时间为 10 s,在配置的时间过后,就可以看到 hive 中的数据了
从 hdfs 上查看 hive 表对应文件的数据,如下图所示
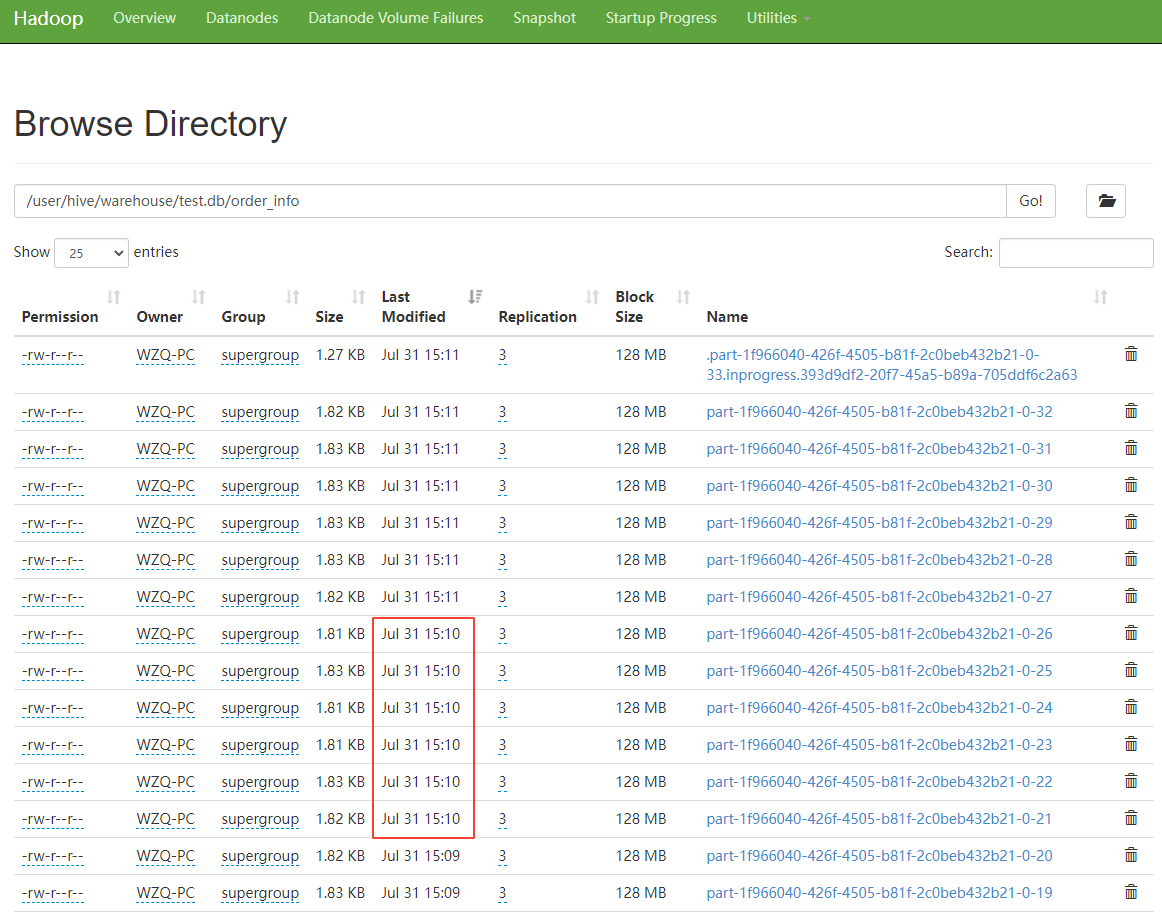
可以看到,1 分钟滚动生成了 6 个文件,最新文件为 .part 开头的文件,在 hdfs 中,以 . 开头的文件,是不可见的,说明这个文件是由于我关闭了 flink sql 任务,然后文件无法滚动造成的。
有关读写 hive 的一些配置和读写 hive 表时其数据的可见性,可以看考读写hive页面。
写入分区表
hive 表
CREATE TABLE `test.order_info_have_partition`(
`product_count` int COMMENT '购买商品数量',
`one_price` double COMMENT '单个商品价格')
PARTITIONED BY (
`minute` string COMMENT '订单时间,分钟级别',
`order_id` int COMMENT '订单id')
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://hadoopCluster/user/hive/warehouse/test.db/order_info_have_partition'
TBLPROPERTIES (
'transient_lastDdlTime'='1659254559')
;
flink sql 语句
-- 如果是 flink-1.13.x ,则需要手动设置该参数
set 'table.dynamic-table-options.enabled' = 'true';
-- 在需要读取hive或者是写入hive表时,必须创建hive catalog。
-- 创建catalog
create catalog hive with (
'type' = 'hive',
'hadoop-conf-dir' = '/data/soft/dlink-0.6.6/hadoop-conf',
'hive-conf-dir' = '/data/soft/dlink-0.6.6/hadoop-conf'
)
;
use catalog hive;
-- 创建连接 kafka 的虚拟表作为 source,此处使用 temporary ,是为了不让创建的虚拟表元数据保存到 hive,可以让任务重启是不出错。
-- 如果想让虚拟表元数据保存到 hive ,则可以在创建语句中加入 if not exist 语句。
CREATE temporary TABLE source_kafka(
event_time TIMESTAMP(3) METADATA FROM 'timestamp',
id integer comment '订单id',
product_count integer comment '购买商品数量',
one_price double comment '单个商品价格'
) WITH (
'connector' = 'kafka',
'topic' = 'data_gen_source',
'properties.bootstrap.servers' = 'node01:9092,node02:9092,node03:9092',
'properties.group.id' = 'for_source_test',
'scan.startup.mode' = 'latest-offset',
'format' = 'csv',
'csv.field-delimiter' = ' '
)
;
insert into test.order_info_have_partition
-- 下面的语法是 flink sql 提示,用于在语句中使用到表时手动设置一些临时的参数
/*+
OPTIONS(
-- 设置分区提交触发器为分区时间
'sink.partition-commit.trigger' = 'partition-time',
-- 'partition.time-extractor.timestamp-pattern' = '$year-$month-$day $hour:$minute',
-- 设置时间提取器的时间格式,要和分区字段值的格式保持一直
'partition.time-extractor.timestamp-formatter' = 'yyyy-MM-dd_HH:mm',
-- 设置分区提交延迟时间,这儿设置 1 分钟,是因为分区时间为 1 分钟间隔
'sink.partition-commit.delay' = '1 m',
-- 设置水印时区
'sink.partition-commit.watermark-time-zone' = 'GMT+08:00',
-- 设置分区提交策略,这儿是将分区提交到元数据存储,并且在分区目录下生成 success 文件
'sink.partition-commit.policy.kind' = 'metastore,success-file',
-- sink 并行度
'sink.parallelism' = '1'
)
*/
select
product_count,
one_price,
-- 不要让分区值中带有空格,分区值最后会变成目录名,有空格的话,可能会有一些未知问题
date_format(event_time, 'yyyy-MM-dd_HH:mm') as `minute`,
id as order_id
from source_kafka
;
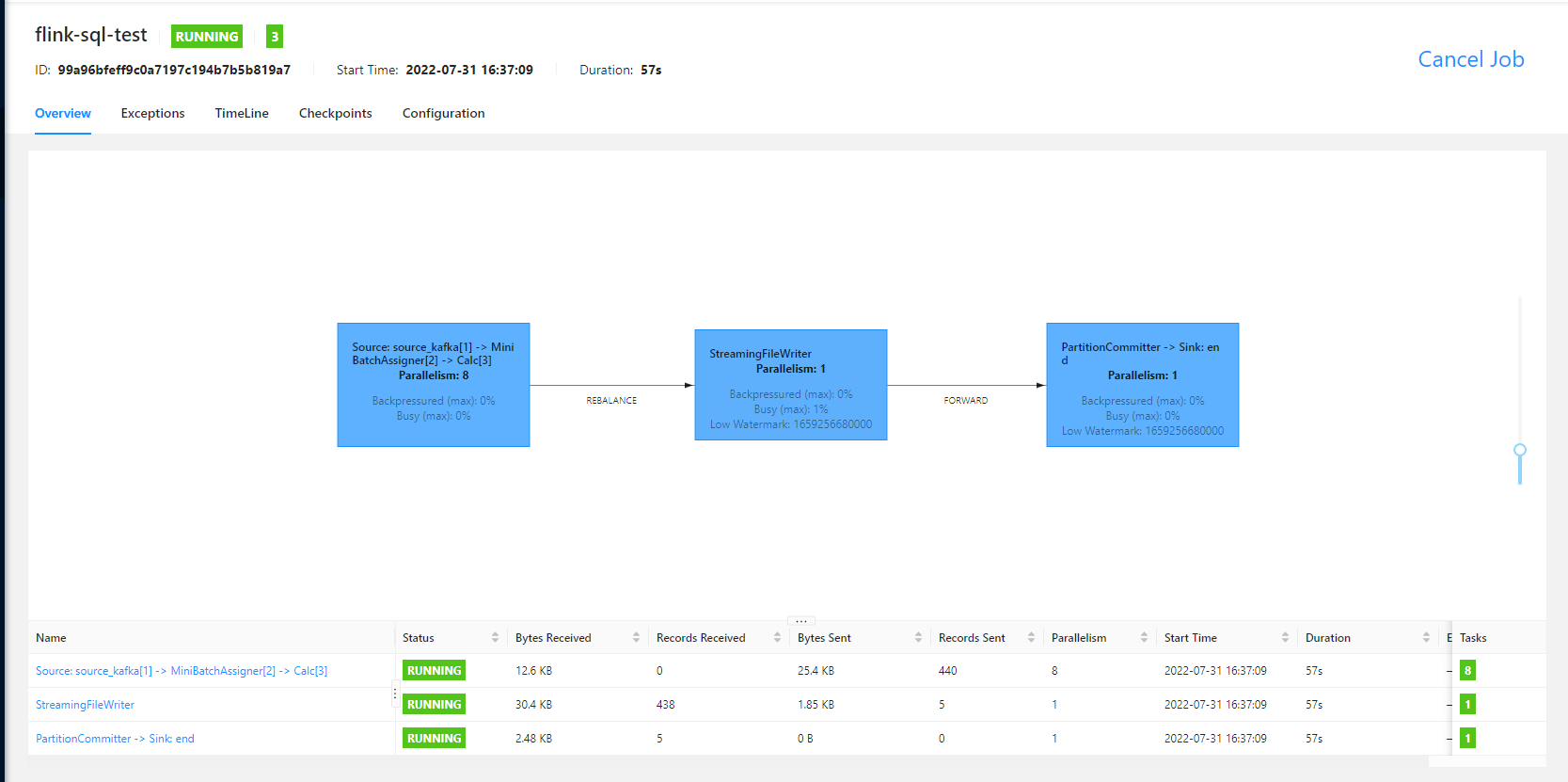
flink sql 任务运行的 UI 界面如下
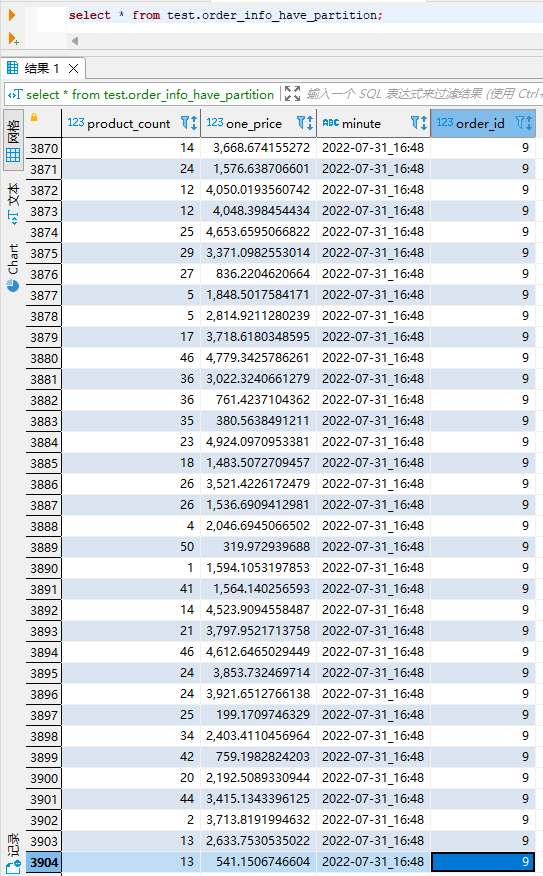
1 分钟之后查看 hive 表中数据,如下
查看 hive 表对应 hdfs 上的文件,可以看到
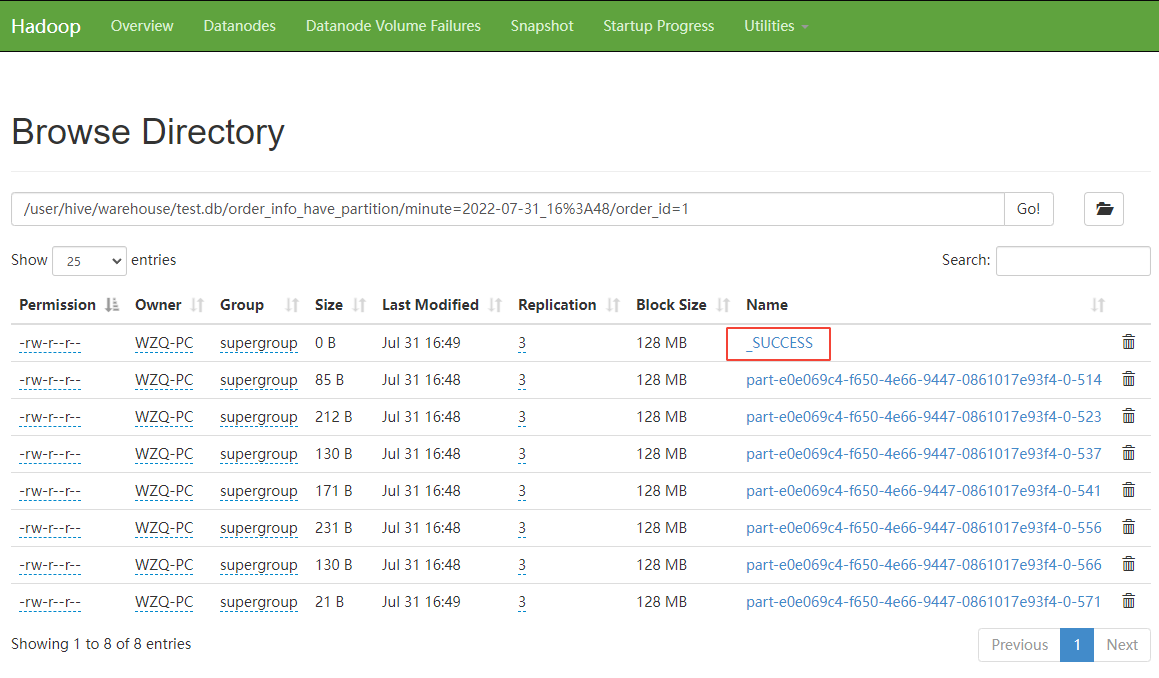
从上图可以看到,具体的分区目录下生成了 _SUCCESS 文件,表示该分区提交成功。