整库同步概述
设计背景
目前通过 FlinkCDC 进行会存在诸多问题,如需要定义大量的 DDL 和编写大量的 INSERT INTO,更为严重的是会占用大量的数据库连接,对 Mysql 和网络造成压力。
Dinky 定义了 CDCSOURCE 整库同步的语法,该语法和 CDAS 作用相似,可以直接自动构建一个整库入仓入湖的实时任务,并且对 source 进行了合并,不会产生额外的 Mysql 及网络压力,支持对任意 sink 的同步,如 kafka、doris、hudi、jdbc 等等
原理
source 合并
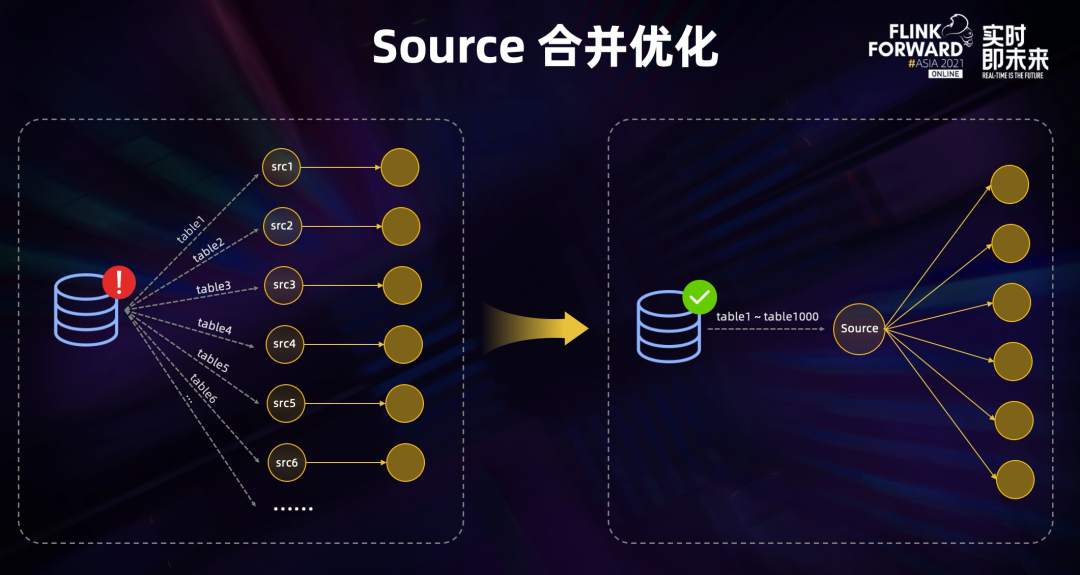
面对建立的数据库连接过多,Binlog 重复读取会造成源库的巨大压力,上文分享采用了 source 合并的优化,尝试合并同一作业中的 source,如果都是读的同一数据源,则会被合并成一个 source 节点。
Dinky 采用的是只构建一个 source,然后根据 schema、database、table 进行分流处理,分别 sink 到对应的表。
元数据映射
Dinky 是通过自身的数据源中心的元数据功能捕获源库的元数据信息,并同步构建 sink 阶段 datastream 或 tableAPI 所使用的 FlinkDDL。
多种 sink 方式
Dinky 提供了各式各样的 sink 方式,通过修改语句参数可以实现不同的 sink 方式。Dinky 支持通过 DataStream 来扩展新的 sink,也可以使用 FlinkSQL 无需修改代码直接扩展新的 sink。
注意事项
一个 FlinkSQL 任务只能写一个 CDCSOURCE,CDCSOURCE 前可写 set、add customjar 和 ddl 语句。
配置项中的英文逗号前不能加空格,需要紧随右单引号。
环境准备
作业配置
- 禁用语句集
- 禁用批模式
- 自 Dinky v1.0.0 开始可以支持 全局变量, 区分整库同步内部变量
#{schemaName}和#{tableName},全局变量则使用${varName}, 请注意区分
整库同步内置变量
注意: 下述变量均为内置变量,不可修改,只能使用,只适用于整库同步
| 变量名 | 说明 | 值示例 | 使用示例 |
|---|---|---|---|
| schemaName | 当前表的 schema 名称,即数据库名称 | test | #{schemaName} |
| tableName | 当前表的表名 | student | #{tableName} |
| pkList | 当前表的主键列表 | id,name | #{pkList} |
Flink 版本区分
- 在 Dinky v1.0.0 之前 dinky-client-1.14 内的整库同步能力最多且主要维护,如果要使用其他 flink 版本的整库同步,如果 SQLSink 不满足需求,需要DataStreamSink 支持,请手动仿照 dlink-client-1.14 扩展相应代码实现,很简单。
- Dinky v1.0.0 之后,整库同步整个模块进行单独维护,不再重依赖于 dinky-client 版本,实现更加灵活. 扩展更加简单方便
其他 FlinkCDC 支持
- Dinky v1.0.0 之后,如需扩展其他 FlinkCDC 支持,可以在
dinky-cdc模块的下属子模块中进行扩展
依赖上传
由于 CDCSOURCE 是 Dinky 封装的新功能,Apache Flink 源码不包含,非 Application 模式提交需要在远程 Flink 集群所使用的依赖里添加一下依赖:
# 将下面 Dinky根目录下 整库同步依赖包放置 $FLINK_HOME/lib下
lib/dinky-client-base-${version}.jar
lib/dinky-common-${version}.jar
extends/flink${flink-version}/dinky/dinky-client-${version}.jar
Application 模式提交
目前已经支持
application,需提前准备好相关jar包,或者和add customjar语法并用。以mysqlcdc-2.3.0为例,需要以下 jar
-
flink-shaded-guava-18.0-13.0.jar
-
HikariCP-4.0.3.jar
-
druid-1.2.8.jar
-
jackson-datatype-jsr310-2.13.4.jar
-
flink-sql-connector-mysql-cdc-2.3.0.jar
add customjar 'flink-shaded-guava-18.0-13.0.jar'
add customjar 'HikariCP-4.0.3.jar'
add customjar 'druid-1.2.8.jar'
add customjar 'jackson-datatype-jsr310-2.13.4.jar'
add customjar 'flink-sql-connector-mysql-cdc-2.3.0.jar'
配置参数
| 配置项 | 是否必须 | 默认值 | 说明 |
|---|---|---|---|
| connector | 是 | 无 | 指定要使用的连接器 |
| hostname | 是 | 无 | 数据库服务器的 IP 地址或主机名 |
| port | 是 | 无 | 数据库服务器的端口号 |
| username | 是 | 无 | 连接到数据库服务器时要使用的数据库的用户名 |
| password | 是 | 无 | 连接到数据库服务器时要使用的数据库的密码 |
| scan.startup.mode | 否 | latest-offset | 消费者的可选启动模式,有效枚举为“initial”和“latest-offset” |
| database-name | 否 | 无 | 此参数非必填 |
| table-name | 是 | 无 | 只支持正则,示例:"test\.student,test\.score",所有表示例:"test\..*" |
| split.enable | 否 | false | 是否开启分库分表模式同步 |
| split.match_number_regex | 否 | 无 | 分库分表匹配正则,如果你是table_1,table_2这种切分策略,可以使用 _[0-9]+ 进行同步,目前也只支持这种策略,单库多表,多库多表,多表单库都可以支持,最终写入的表则是去掉_,如 source: db_1,tb_2, sink: db,tb |
| split.max_match_value | 否 | 无 | 分库分表的最大匹配的最大上限值,比如table_1 ...table_300,往后的table_301并不属于切分策略,则可设置为 301 |
| source.* | 否 | 无 | 指定个性化的 CDC 配置,如 source.server-time-zone 即为 server-time-zone 配置参数。 |
| debezium.* | 否 | 无 | 支持debezium参数,示例:'debezium.skipped.operations'='d' 即过滤源数据库删除操作日志。 |
| jdbc.properties.* | 否 | 无 | 连接jdbc的url参数,示例:'jdbc.properties.useSSL' = 'false' 连接url效果: jdbc:mysql://ip:3306/db?useSSL=false 数据库连接参数 |
| checkpoint | 否 | 无 | 单位 ms |
| parallelism | 否 | 无 | 任务并行度 |
| sink.connector | 是 | 无 | 指定 sink 的类型,如 datastream-kafka、datastream-doris、datastream-hudi、kafka、doris、hudi、jdbc 等等,以 datastream- 开头的为 DataStream 的实现方式 |
| sink.sink.db | 否 | 无 | 目标数据源的库名,不指定时默认使用源数据源的库名 |
| sink.table.prefix | 否 | 无 | 目标表的表名前缀,如 ODS_ 即为所有的表名前拼接 ODS_ |
| sink.table.suffix | 否 | 无 | 目标表的表名后缀 |
| sink.table.upper | 否 | false | 目标表的表名全大写 |
| sink.table.lower | 否 | false | 目标表的表名全小写 |
| sink.auto.create | 否 | false | 目标数据源自动建表,目前只支持 Mysql,其他可自行扩展 |
| sink.timezone | 否 | UTC | 指定目标数据源的时区,在数据类型转换时自动生效 |
| sink.column.replace.line-break | 否 | false | 指定是否去除换行符,即在数据转换中进行 REGEXP_REPLACE(column, '\n', '') |
| sink.* | 否 | 无 | 目标数据源的配置信息,同 FlinkSQL,使用 ${schemaName} 和 ${tableName} 可注入经过处理的源表名 |
| sink[N].* | 否 | 无 | N代表为多数据源写入, 默认从0开始到N, 其他配置参数信息参考sink.*的配置. |
支持debezium参数
CDCSOURCE 支持 debezium.* 参数。该示例为将 mysql 整库同步到另一个 mysql 数据库,添加'debezium.skipped.operations'='d'
参数,使得采集日志过滤掉源数据库删除操作,让目标库保留全量数据。如需使用该参数,在配置项中添加即可。