Flink作业
本章节介绍Flink Sql与Flink Jar作业开发
基础作业配置
作业配置
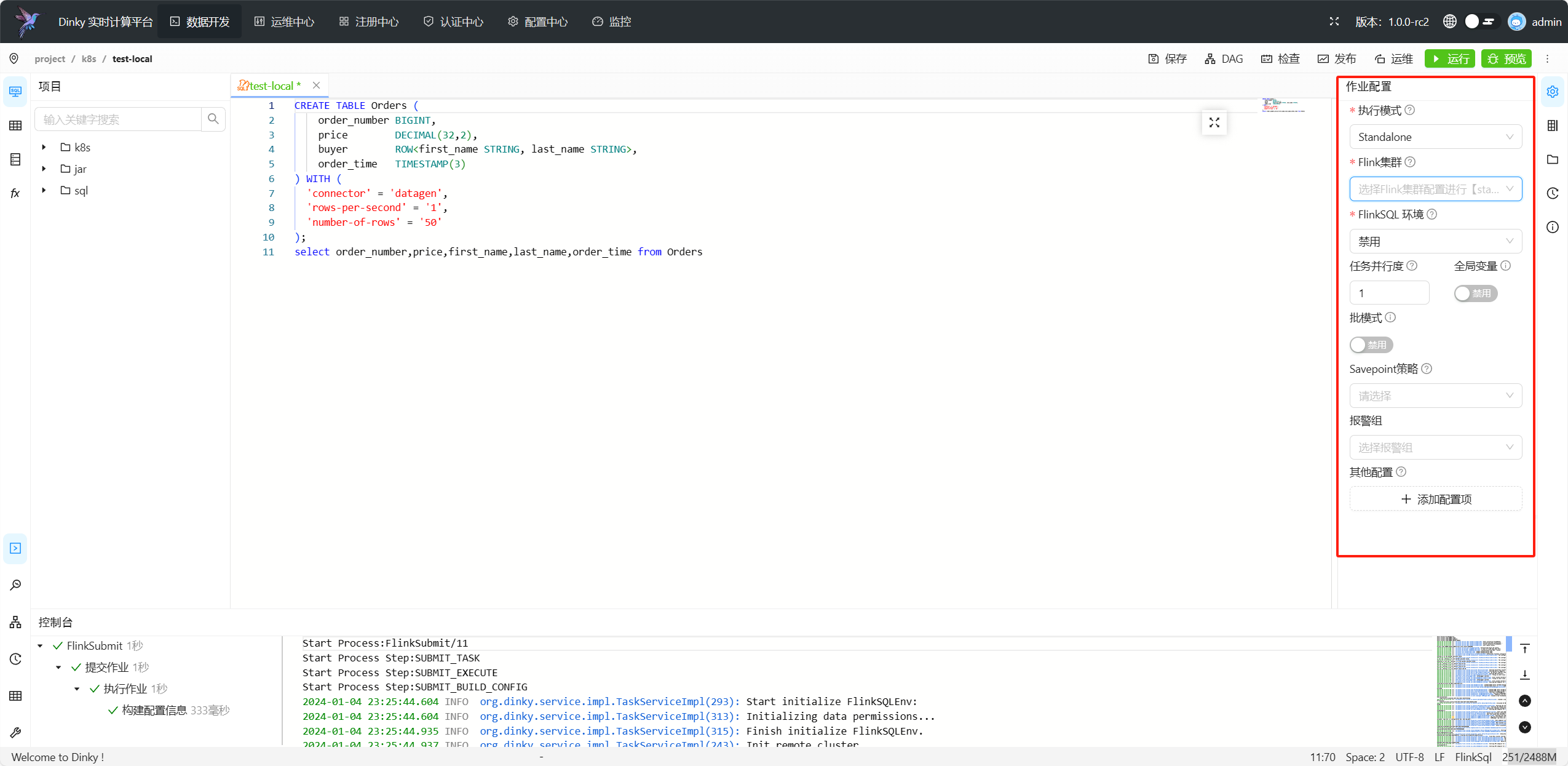 该面板仅在 FlinkSQL 与 Flink Jar 类型作业需要配置,您可以根据具体需求配置参数,参数设置如下
该面板仅在 FlinkSQL 与 Flink Jar 类型作业需要配置,您可以根据具体需求配置参数,参数设置如下
| 是否必填 | 配置项 | 备注 |
|---|---|---|
| 是 | 执行模式 | 指定 FlinkSQL 的执行模式,默认为local,支持以下几种运行模式** Local Standalone Yarn / Yarn Session Yarn Prejob / Yarn Application K8s Application / K8s Session** |
| 是 | Flink集群 | 除Local模式外,Standalone与Session模式需要选择对应的集群实例,Application与PreJob模式需要选择对应的集群配置,具体配置方法参考注册中心内容 |
| 否 | FlinkSQL 环境 | 选择当前 FlinkSQL 执行环境或Catalog,默认无,请参考FlinkSQLEnv 作业或Catalog章节 |
| 是 | 任务并行度 | 设置Flink任务的并行度,默认为 1 |
| 否 | 全局变量 | 默认禁用,开启 FlinkSQL 全局变量,以${}进行调用 |
| 否 | 批模式 | 默认禁用,开启后启用 Batch Mode |
| 否 | SavePoint 策略 | 默认禁用,策略包括: 最近一次 最早一次 指定一次 |
| 否 | 报警组 | 报警组配置详见报警管理 |
| 否 | 其他配置 | 其他的 Flink 作业配置,具体可选参数,详见Flink 官网 |
使用Local模式的作业运行在那里?
Dinky内置了一个Flink MiniCluster,提交Local模式作业后,Dinky会启动一个单机Flink MiniCluster,作业被运行在此集群上, 该集群资源受限,仅适用于快速体验或临时测试Flink任务,不建议在生产环境使用,生产作业请使用其他模式。
其他配置的列表里没有我需要的参数怎么办?
为防止误输入,错误输入,Dinky提供了常用的Flink配置,如果您需要的参数不存在,可以修改dinky安装目录下的 dinky-loader/FlinkConfClass
文件,
新增一行为该参数所在flink源码中的全路径类名,重启dinky即可。
除此之外,您还可以在 注册中心-->文档-->新建文档 中添加您需要的配置,类型选择
Flink参数,添加完成后即可在配置列表中找到刚刚添加的Flink参数,具体请参考注册中心文档管理模块
保存点
Dinky 提供 FlinkSQL 在通过 智能停止 作业时,自动触发savepoint。也可以在运维中心手动触发,触发成功后会保存结果并记录在这里
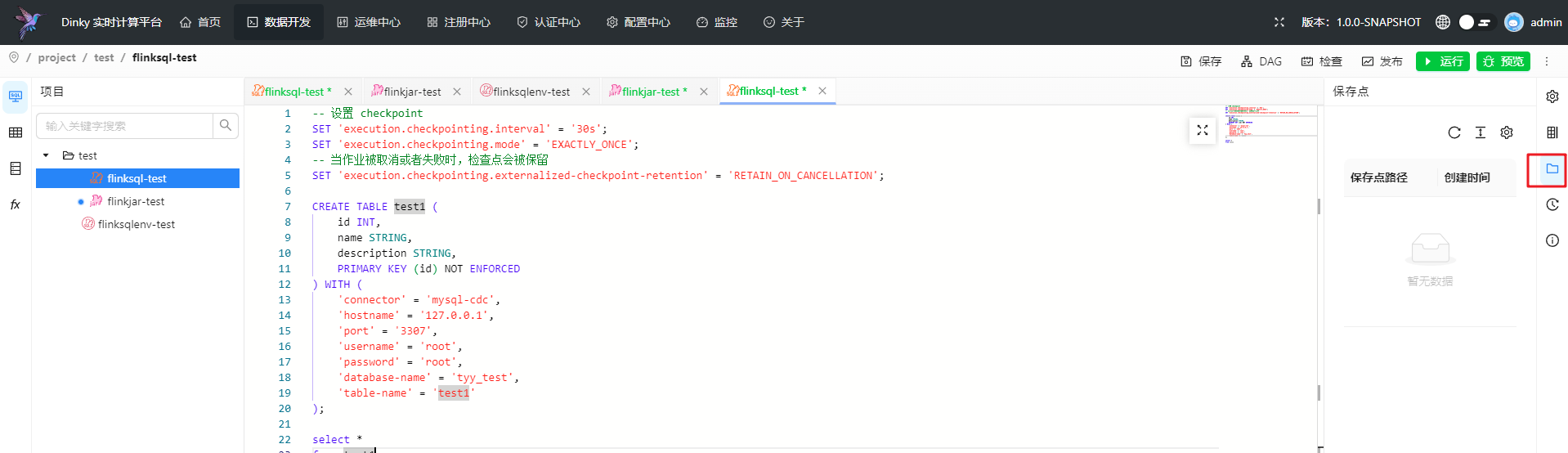
版本历史
在创建作业后,点击发布会自动创建一个历史版本,用于记录历史并回退
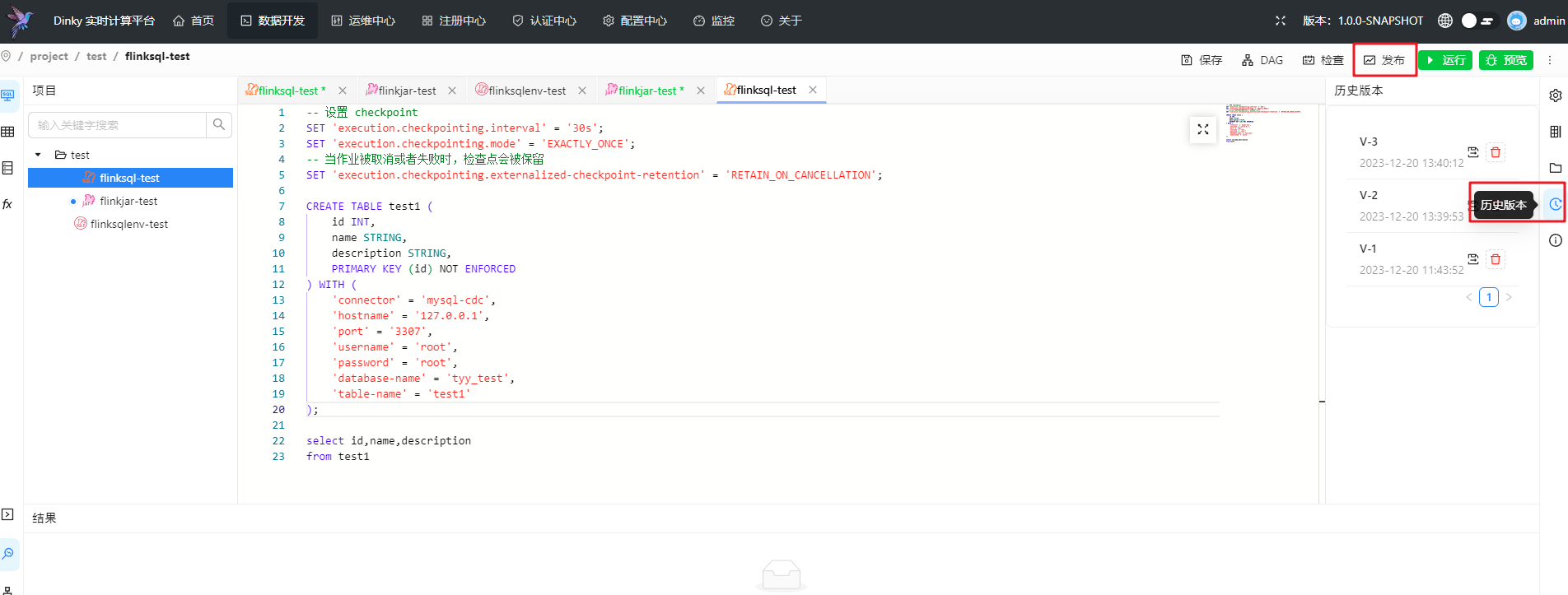
单击历史版本即可查看当前版本与所选版本的代码差异
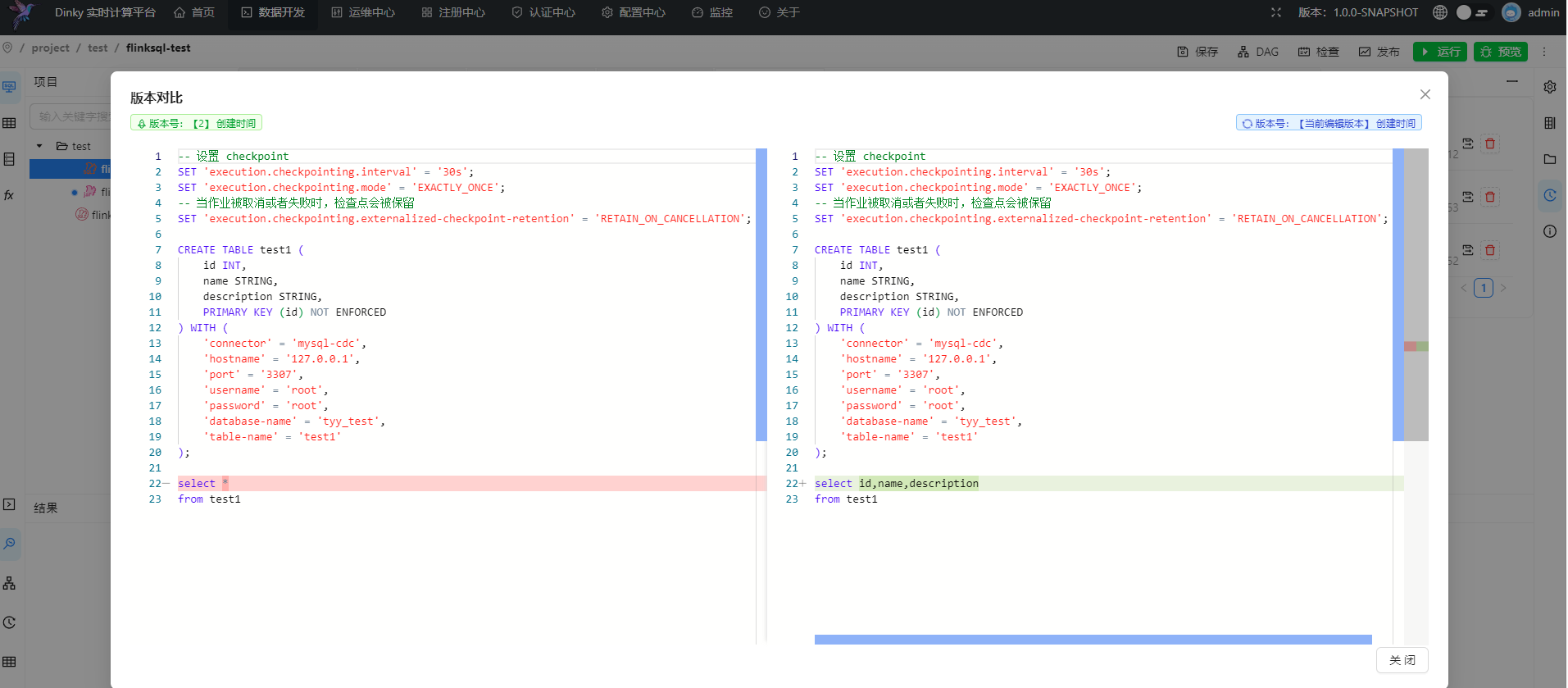
可点击此处回滚版本
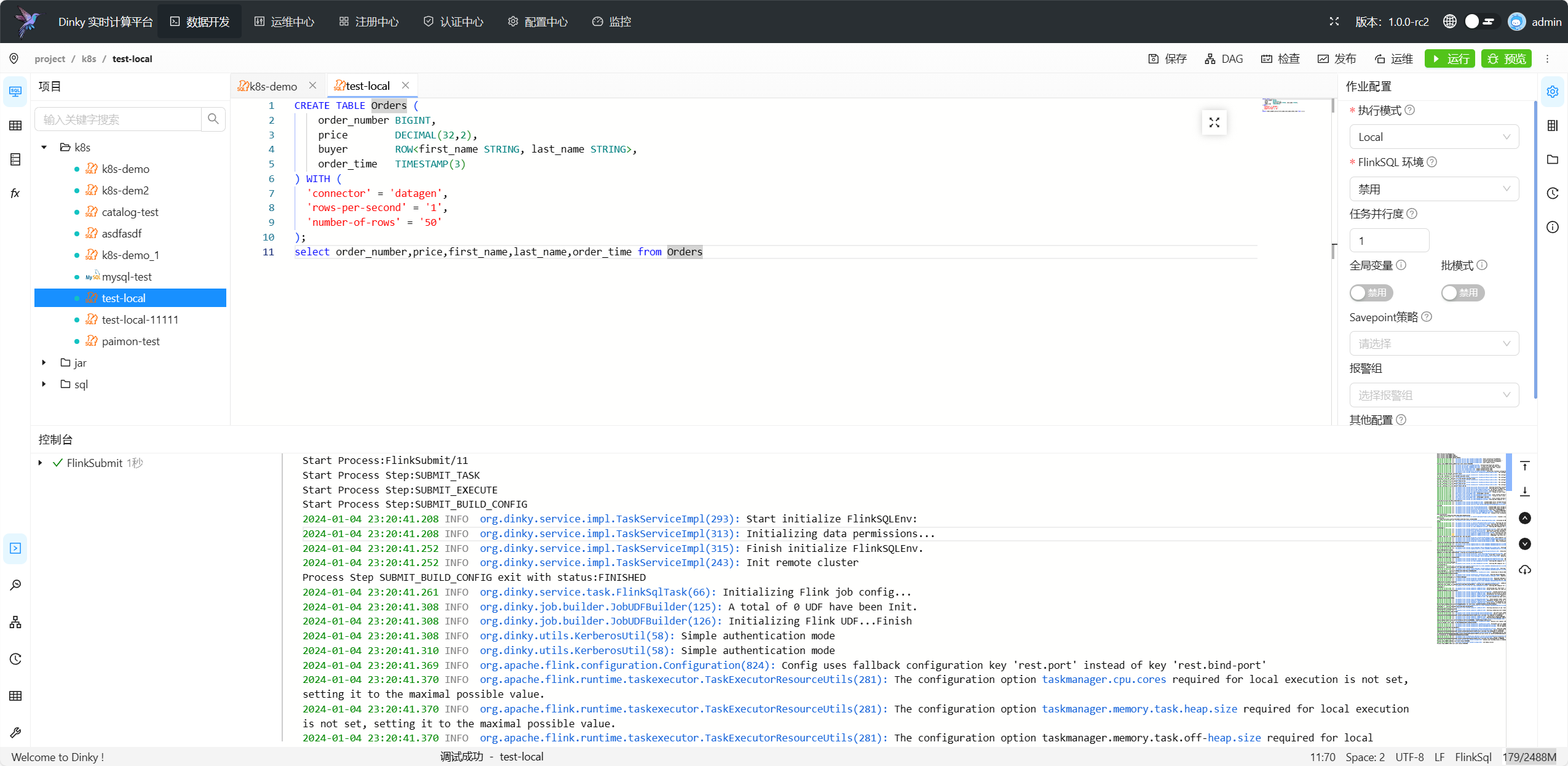
运行作业
单击左上角执行按钮即可提交任务到指定集群,提交为同步操作,运行过程下方控制台会实时打印执行日志,如果作业运行失败,请参考日志内容进行定位。
请勿将Select语句作为FlinkSQL作业提交,Select语句请使用预览功能,详见下方预览功能章节
作业预览
在Flink
Sql开发过程中,我们经常需要查看作业所产出的数据,Dinky提供了预览功能,可以在开发过程中实时查看数据,对于select语句或开启的SinkMock的insert语句,点击右上角预览
即可。
同时你也可以对预览功能进行配置,如下图
//: # (TODO: update pic)
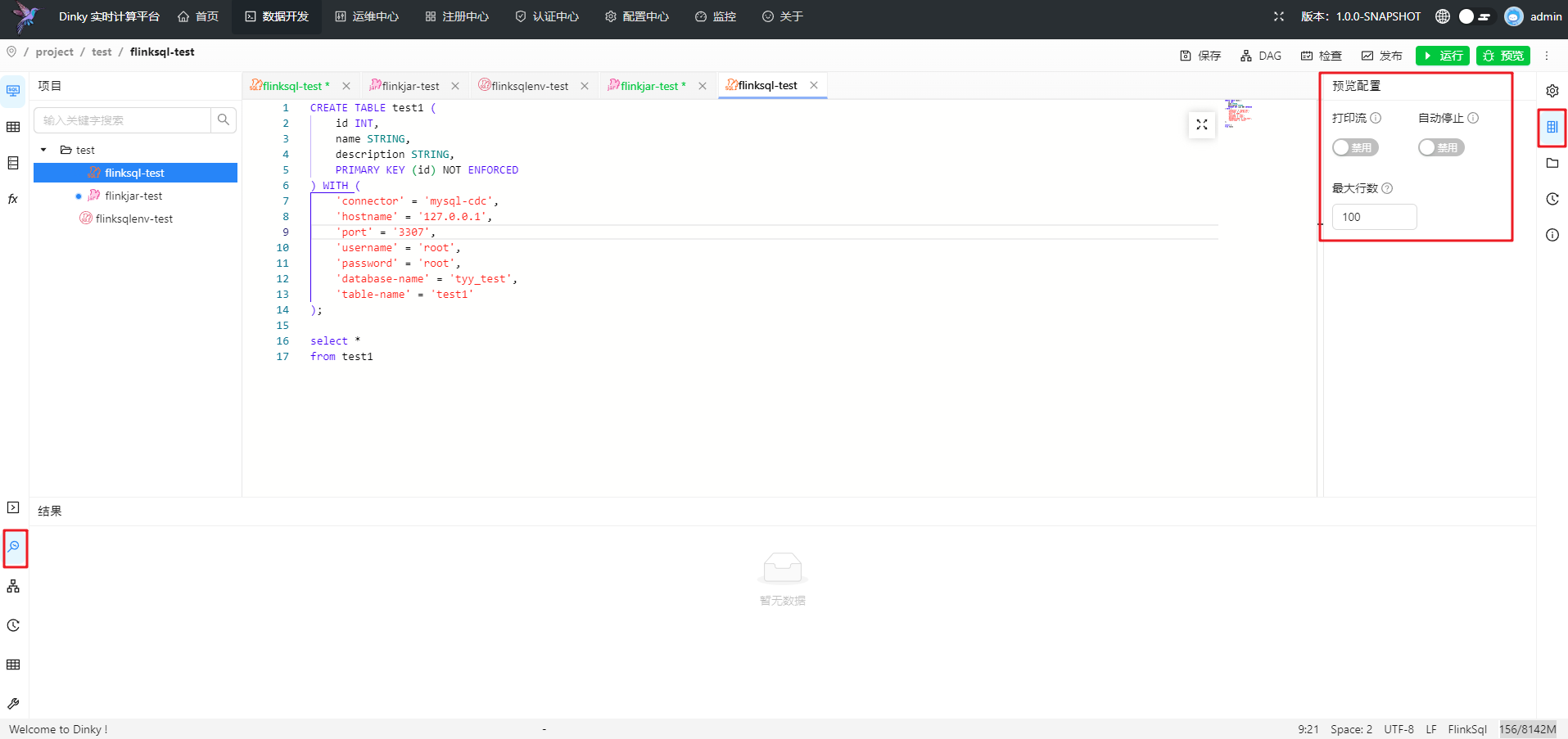
参数设置如下
| 是否必填 | 配置项 | 备注 |
|---|---|---|
| 否 | 打印流 | 默认禁用,开启打印流将同步运行并返回含有op字段信息的 ChangeLog 默认不开启则返回最终结果 |
| 否 | 最大行数 | 预览数据的最大行数,默认100 |
| 否 | 自动停止 | 默认禁用,开启自动停止将在捕获最大行记录数后自动停止 |
| 否 | 开启SinkMock | 默认启用,将Insert语句所写入的表进行Mock,使得调试过程中不会向线上环境执行写入,但可以通过dinky预览Sink结果 |
提交成功后会切换到结果选项卡,点击 获取最新数据 ,即可查看 Select/Insert 语句的执行结果。
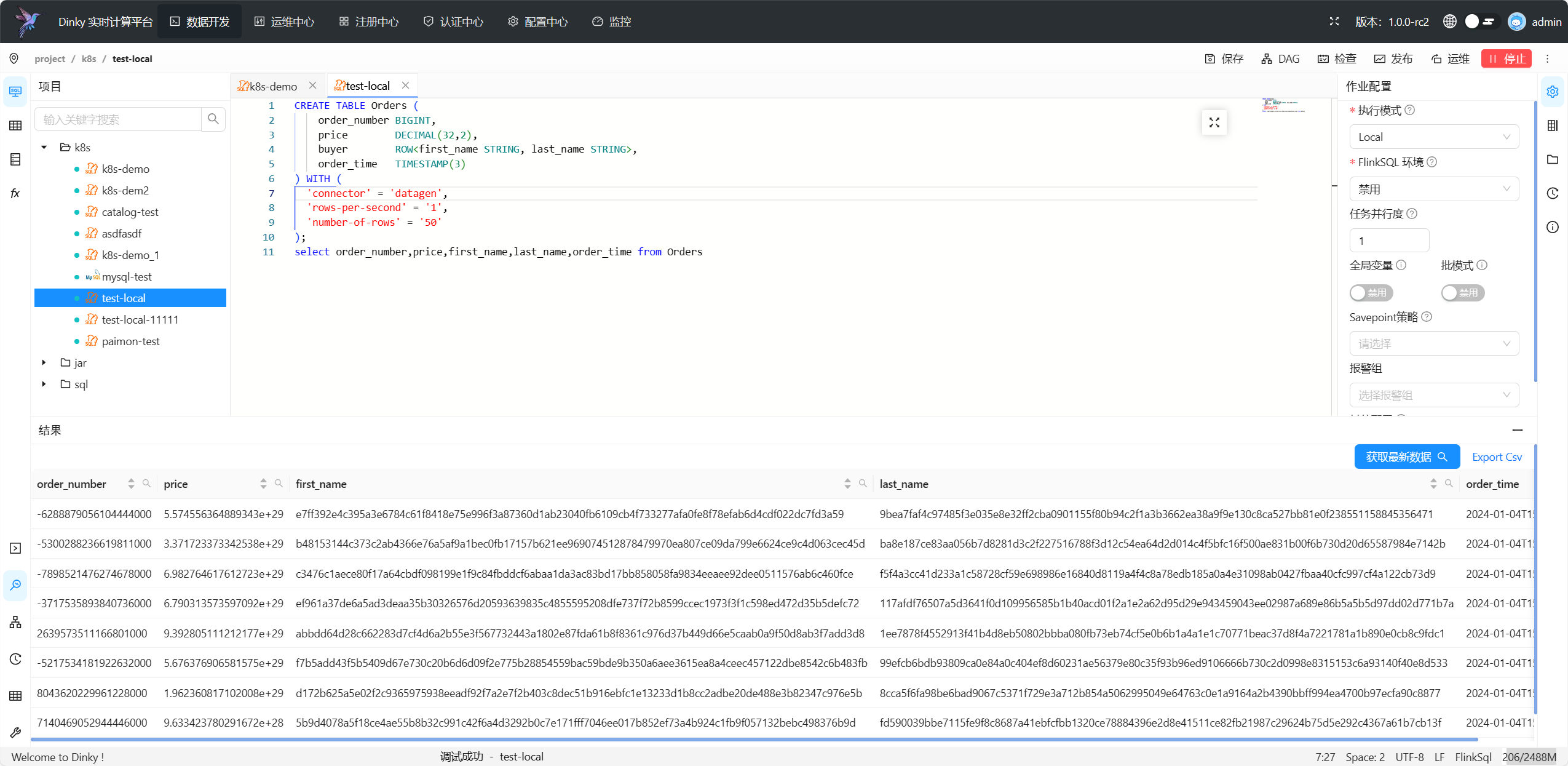
-
执行模式必须是 Local、Standalone、Yarn Session、Kubernetes Session 其中的一种;
-
未开启MockSink时,除 SET 和 DDL 外,必须只提交一个 SELECT 或 SHOW 或 DESC 语句;
-
开启MockSink,并提交了至少一个Insert语句;
-
作业必须是提交成功并且返回 JID,同时在远程集群可以看到作业处于 RUNNING 或 FINISHED 状态;
-
Dinky 重启后,之前的预览结果将失效
工具栏使用
在数据开发页面右上方的工具栏可帮助用户快速对作业进行操作
 具体含义如下
具体含义如下
| 名称 | 作用 | 备注 |
|---|---|---|
| 保存 | 保存当前作业 | |
| DAG | 获取Flink sql流程图 | |
| 检查 | 对sql进行校验 | |
| 发布 | 发布任务 | 任务发布后不允许进行修改 |
| 推送 | 推送至 DolphinScheduler | 该按钮仅在以下条件全部满足时方可展示/使用, 条件: 1. 启用了DolphinScheduler,且配置正确 2. 任务已经发布 |
| 运维 | 跳转运维页面 | 作用未运行不会有此按钮 |
| 运行 | 提交作业 | |
| 预览 | 预览作业数据 |
Flink sql作业
编写FlinkSql语句
--创建源表datagen_source
CREATE TABLE datagen_source
(
id BIGINT,
name STRING
)
WITH ( 'connector' = 'datagen');
--创建结果表blackhole_sink
CREATE TABLE blackhole_sink
(
id BIGINT,
name STRING
)
WITH ( 'connector' = 'blackhole');
--将源表数据插入到结果表
INSERT INTO blackhole_sink
SELECT id,
name
from datagen_source;
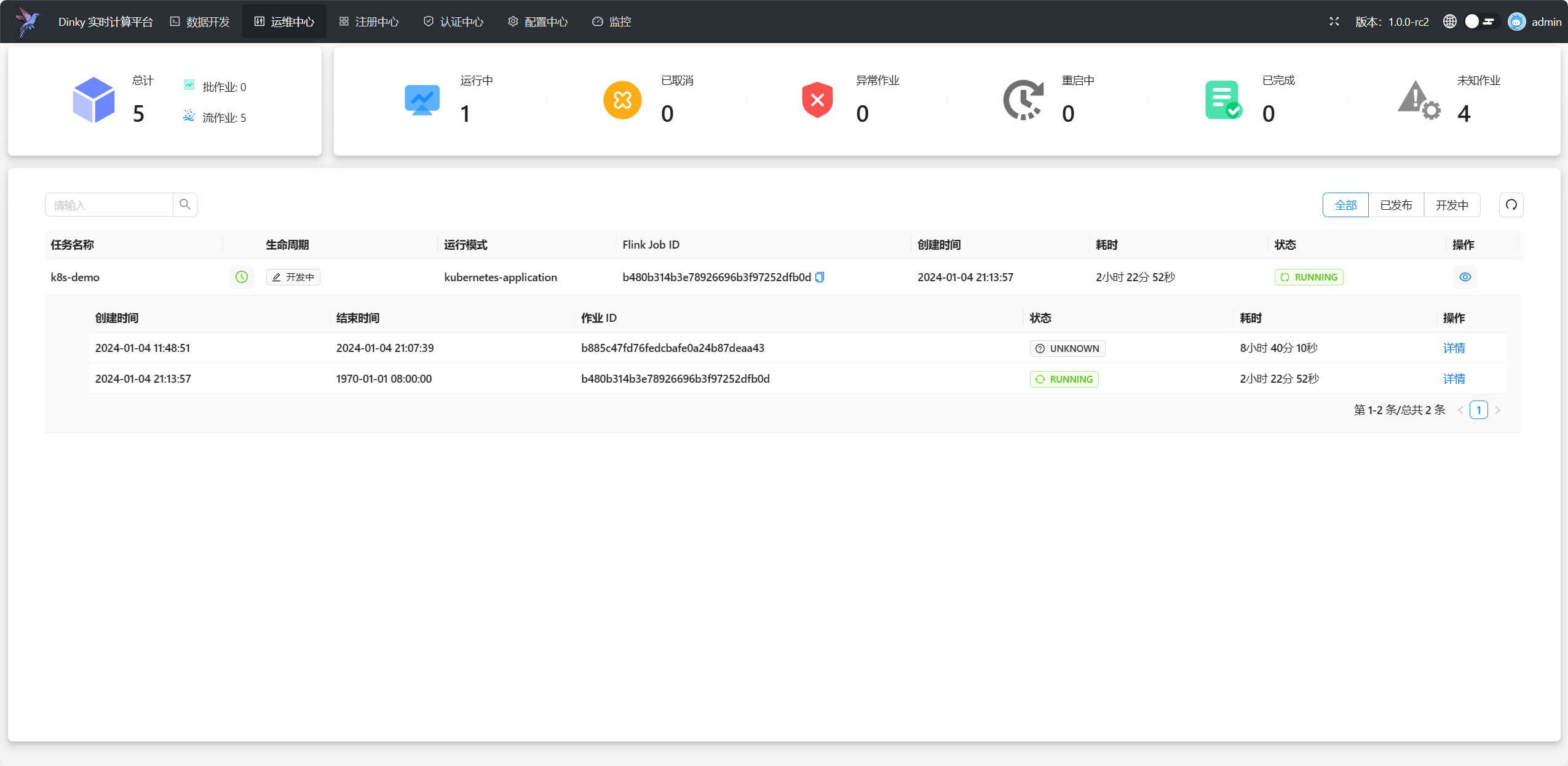
点击提交按钮,即可提交任务到集群,任务提交完成,我们可以进入运维中心页面,状态为Running表示运行成功。
Flink JAR作业
编写FlinkSql语句
- 此为dinky增强扩展语法, 详见 Flink SQL 扩展语法
- 此语法仅能在Flink jar作业中使用,请注意创建作业时选择作业类型为
FlinkJar
语法结构
EXECUTE JAR WITH (
'uri'='<jar_path>.jar', -- jar文件路径 必填
'main-class'='<main_class>', -- jar作业运行的主类 必填
'args'='<args>', -- 主类入参 可选
'parallelism'='<parallelism>', -- 任务并行度 可选
);
样例代码1
set 'execution.checkpointing.interval'='21 s';
EXECUTE JAR WITH (
'uri'='rs:/jar/flink/demo/SocketWindowWordCount.jar',
'main-class'='org.apache.flink.streaming.examples.socket',
'args'=' --hostname localhost ',
'parallelism'='',
);
- 以上示例中, uri 的值为 rs:/jar/flink/demo/SocketWindowWordCount.jar, 该值为资源中心中的资源路径, 请确保资源中心中存在该资源,请忽略资源中心 Root 节点(该节点为虚拟节点)
- 如果要读取 S3,HDFS,LOCAL 等存储上面的文件均可通过rs协议进行桥接使用,请参考 资源管理 中 rs 协议使用方式
样例代码2
EXECUTE JAR WITH (
'uri'='rs:/paimon-flink-action-0.7.0-incubating.jar',
'main-class'='org.apache.paimon.flink.action.FlinkActions',
'args'='compact --warehouse hdfs:///tmp/paimon --database default --table use_be_hours_2'
);
- 注意填写main-class,不能为空
- 注意args中的空格填写