Dinky 与 Flink 集成
本文档介绍 Dinky 与 Flink 集成的使用方法,
如果您是 Dinky 的新用户, 请先阅读 本文档, 以便更好的搭建 Dinky 环境
如果您已经熟悉 Dinky 并已经部署了 Dinky, 请跳过本文档的前置要求部分, 直接阅读 Dinky 与 Flink 集成部分
注意: 本文档基于 Dinky 1.0.0+ 版本编写, 请确保 Dinky 版本 >= 1.0.0
前置要求
- JDK 1.8/11
- Dinky 1.0.0+
- MySQL 5.7+
- Flink 1.14+(Dinky v1.0.0 支持 Flink 1.14+ 及以上版本)
Flink 环境准备
本案例以 Flink 1.18.0 模式采用 Standalone 模式为例, 请根据实际情况自行选择部署模式,各个模式的部署方案自行参考 Flink 官方文档/百度/谷歌/必应...
下载 Flink
wget https://archive.apache.org/dist/flink/flink-1.18.0/flink-1.18.0-bin-scala_2.12.tgz
解压 Flink
tar -zxvf flink-1.18.0-bin-scala_2.12.tgz
mv flink-1.18.0 flink
配置环境变量
vim ~/.bashrc
# 末尾加入以下内容
export FLINK_HOME=/opt/flink
export PATH=$PATH:$FLINK_HOME/bin
# 使环境变量生效
source ~/.bashrc
启动 Flink
cd flink
./bin/start-cluster.sh
验证
页面访问: http://ip:8081
Dinky 环境准备
下载 Dinky
wget https://github.com/DataLinkDC/dinky/releases/download/v1.0.0-rc2/dinky-release-1.0.0-rc2.tar.gz
解压 Dinky
tar -zxvf dinky-release-1.0.0-rc2.tar.gz
mv dinky-release-1.0.0-rc2 dinky
配置数据库
本案例以 MySQL 为例, 支持 MySQL 5.7+, PostgreSQL , 或者直接使用内置 H2 数据库,请根据实际情况自行选择数据库,各个数据库的部署方案自行参考官方文档/百度/谷歌/必应...
如果选择使用 H2 数据库, 请跳过本节 ,MySQL 安装步骤在这里不再赘述, 请自行百度/谷歌/必应...
安装完成之后 创建 dinky 数据库, 并设置账户密码,也可使用默认账户密码, 创建完成数据库之后需要执行初始化 sql 脚本, 脚本路径为 dinky/sql/dinky-mysql.sql
修改 conf/application-mysql.yml 文件, 修改数据库连接信息
spring:
datasource:
url: jdbc:mysql://${MYSQL_ADDR:127.0.0.1:3306}/${MYSQL_DATABASE:dinky}?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&useSSL=false&zeroDateTimeBehavior=convertToNull&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
username: ${MYSQL_USERNAME:dinky}
password: ${MYSQL_PASSWORD:dinky}
driver-class-name: com.mysql.cj.jdbc.Driver
修改 conf/application.yml 文件, 修改数据库连接使用方式
spring:
# Dinky application name
application:
name: Dinky
profiles:
# The h2 database is used by default. If you need to use other databases, please set the configuration active to: mysql, currently supports [mysql, pgsql, h2]
# If you use mysql database, please configure mysql database connection information in application-mysql.yml
# If you use pgsql database, please configure pgsql database connection information in application-pgsql.yml
# If you use the h2 database, please configure the h2 database connection information in application-h2.yml,
# note: the h2 database is only for experience use, and the related data that has been created cannot be migrated, please use it with caution
active: mysql #[h2,mysql,pgsql] 修改此处,默认为 h2, 修改为 mysql
include: jmx
Dinky 与 Flink 集成
修改完数据库连接配置不要着急启动,接下来 Dinky 与 Flink 集成
- 将 Flink 的 lib 目录下的 所有 jar 包复制到 Dinky 的 extends 目录下
cp -r /opt/flink/lib/* /opt/dinky/extends/
- 添加/修改一些额外的依赖
cd /opt/dinky/extends/
# 添加 common-cli 依赖, 否则会出现异常
wget https://repo1.maven.org/maven2/commons-cli/commons-cli/1.6.0/commons-cli-1.6.0.jar
# 为什么要下载这个 jar 包, 因为内部有些冲突的已经被删除掉了,
# 注意: 如果无需 hadoop 环境, 可以不下载这个 jar 包, 但是如果需要 hadoop 环境, 必须下载这个 jar 包
# 下载 Dinky 群公告 内的 flink-shaded-hadoop-3-uber-3.1.1.7.2.1.0-327-9.0.jar
# 将 flink-table-planner-loader 包换成 flink-table-planner 包
# 先删除 flink-table-planner-loader 包
rm -rf /opt/dinky/extends/flink-table-planner-loader-1.18.0.jar
rm -rf /opt/flink/lib/flink-table-planner-loader-1.18.0.jar
# 将 flink-table-planner 包复制到 extends 目录下和 flink lib 目录下
cp /opt/flink/opt/flink-table-planner_2.12-1.18.0.jar /opt/flink/lib/
cp /opt/flink/opt/flink-table-planner_2.12-1.18.0.jar /opt/dinky/extends/
以上依赖修改完成之后, 需要重启 Flink
启动 Dinky
当你阅读到这里的时候, 请确保你已经完成了上述的所有步骤, Flink 已经启动, 并可以正常访问. 请先不要添加其他连接器依赖
下述的命令中 1.18 代表 Flink 版本, 请根据实际情况修改 支持 1.14 , 1.15, 1.16 , 1.17 , 1.18,
通过指定版本使 Dinky 加载对应版本的 Flink 依赖, 以便 Dinky 能够正常与 Flink 集成。
cd dinky
# 1.18 代表 Flink 版本, 请根据实际情况修改 支持 1.14 , 1.15, 1.16 , 1.17 , 1.18,
./auto.sh start 1.18
验证
页面访问: http://ip:8888 正常访问至登录页面, 证明 Dinky 已经启动成功, 请使用默认账户密码登录, 默认账户密码为 admin/admin
Datagen 任务 Demo
创建 Datagen 任务
- 进入
数据开发-> 项目 -> 新建根目录 名称自行定义 - 右键
新建作业-> 类型选择FlinkSQL-> 输入名称 -> 输入描述(可选) 点击完成 - 在编辑器中输入如下代码
# checkpoint 配置 自行根据实际情况修改, 以下为示例
set execution.checkpointing.checkpoints-after-tasks-finish.enabled=true;
SET pipeline.operator-chaining=false;
set state.backend.type=rocksdb;
set execution.checkpointing.interval=8000;
set state.checkpoints.num-retained=10;
set cluster.evenly-spread-out-slots=true;
DROP TABLE IF EXISTS source_table3;
CREATE TABLE IF NOT EXISTS
source_table3 (
`order_id` BIGINT,
`product` BIGINT,
`amount` BIGINT,
`order_time` as CAST(CURRENT_TIMESTAMP AS TIMESTAMP(3)),
WATERMARK FOR order_time AS order_time - INTERVAL '2' SECOND
)
WITH
(
'connector' = 'datagen',
'rows-per-second' = '1',
'fields.order_id.min' = '1',
'fields.order_id.max' = '2',
'fields.amount.min' = '1',
'fields.amount.max' = '10',
'fields.product.min' = '1',
'fields.product.max' = '2'
);
DROP TABLE IF EXISTS sink_table5;
CREATE TABLE IF NOT EXISTS
sink_table5 (
`product` BIGINT,
`amount` BIGINT,
`order_time` TIMESTAMP(3),
`one_minute_sum` BIGINT
)
WITH
('connector' = 'print');
INSERT INTO
sink_table5
SELECT
product,
amount,
order_time,
SUM(amount) OVER (
PARTITION BY
product
ORDER BY
order_time
RANGE BETWEEN INTERVAL '1' MINUTE PRECEDING
AND CURRENT ROW
) as one_minute_sum
FROM
source_table3;
- 配置右侧
任务配置,请根据实际情况填写,如对参数不了解, 请鼠标悬浮至表单的每项 label 右侧的?查看帮助信息 - 点击保存按钮/ctrl+s 保存任务
- 可自行点击 DAG/检查 等按钮查看任务的 DAG 图和检查该作业的语法是否正确
- 以上完成之后,点击运行按钮, 等待任务运行完成, 可以在
运维中心中查看任务的运行状态/直接点击运行按钮左侧的运维按钮,即可跳转至运维中心该任务的详情页面查看运行状态,如下图: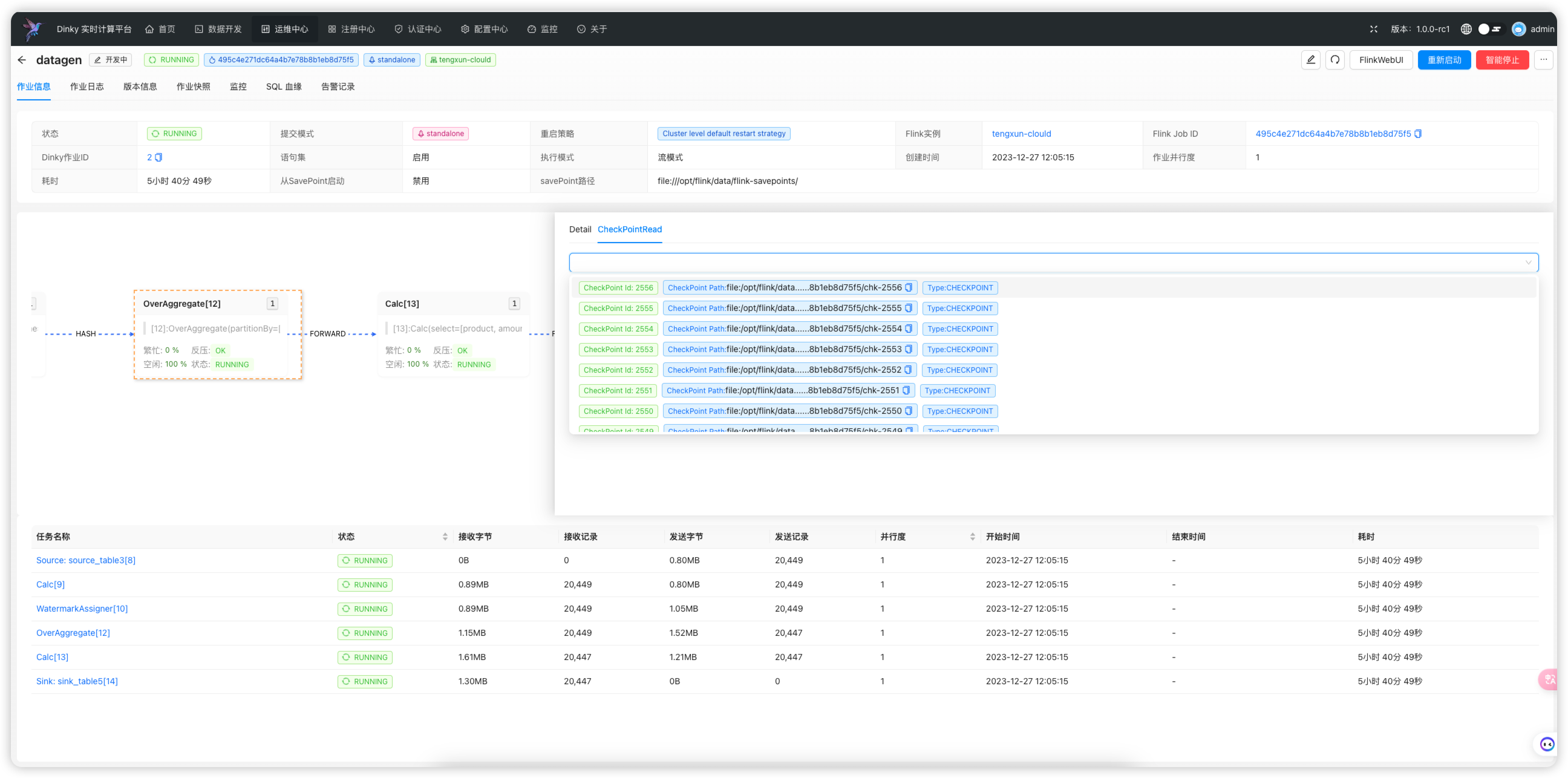
其他连接器集成
以下连接器集成方式与上述 Datagen 任务集成方式一致, 请自行参考