Python UDF
环境准备
-
需要把
${FLINK_HOME}/opt/flink-python_${scala-version}-${flink-version}.jar放入到${FLINK_HOME}/lib/和${Dinky_HOME}/plugins/下面。如下: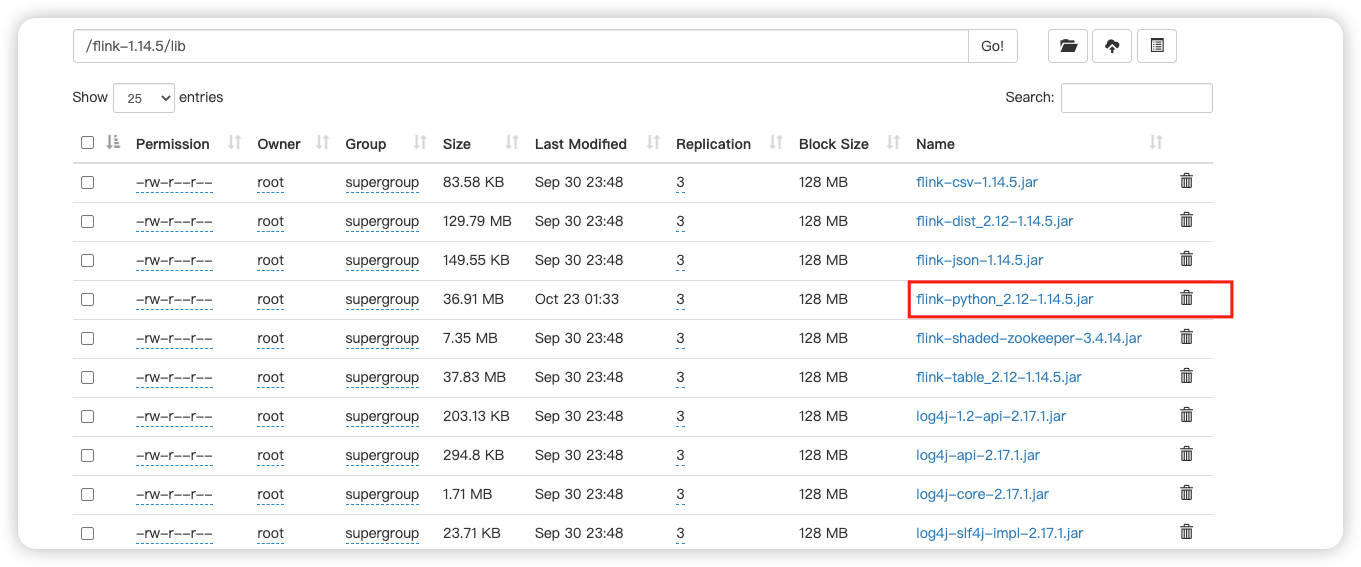
-
在 Dinky 安装目录
conf/application.yml下,配置 python 执行环境。例如 :/usr/bin/python3.6
作业创建
- 选择 Python 作业,并输入对应参数
python_udf_test
python截取函数
SubFunction.f
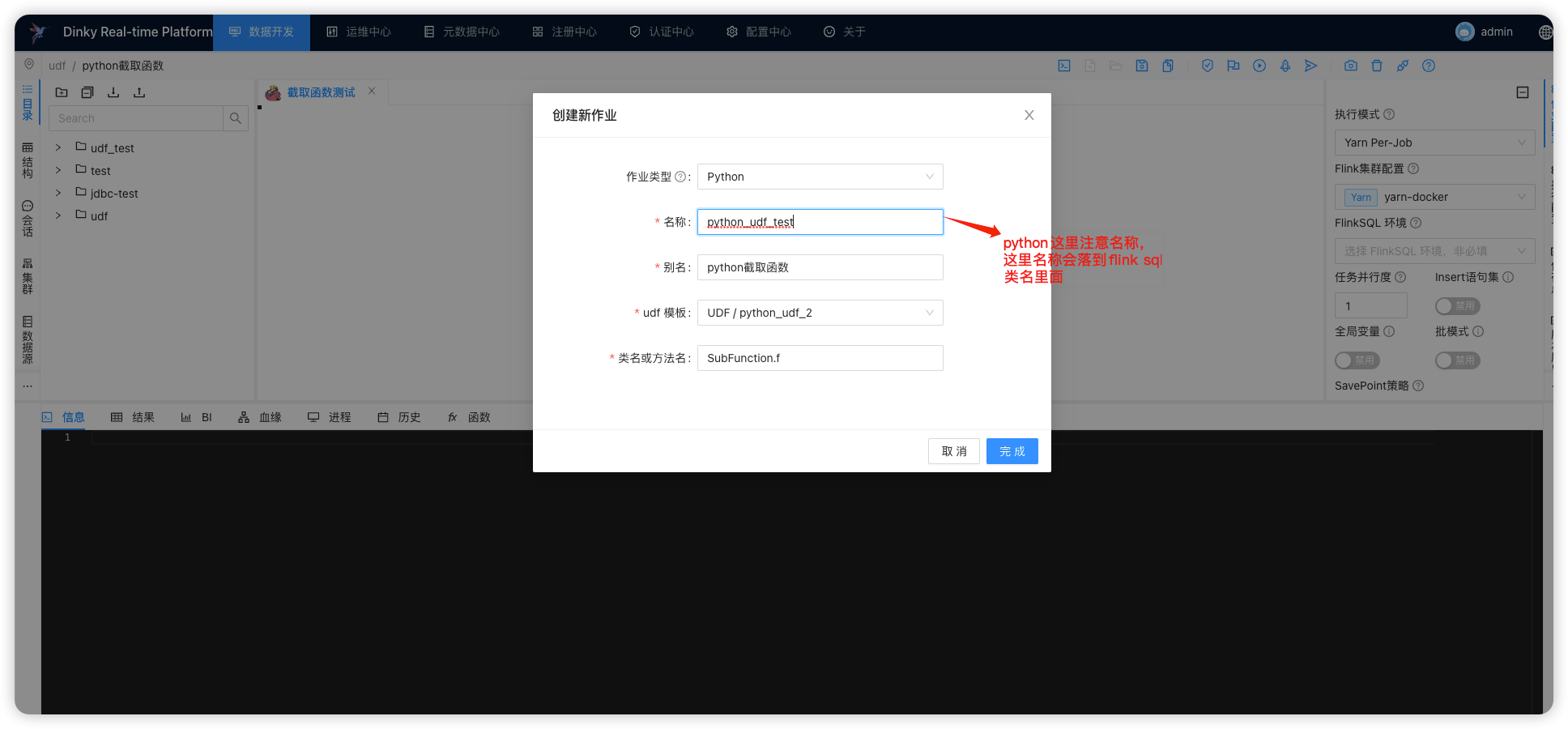
注意名称,底层实现逻辑即通过名称创建 py 文件,如: python_udf_test.py
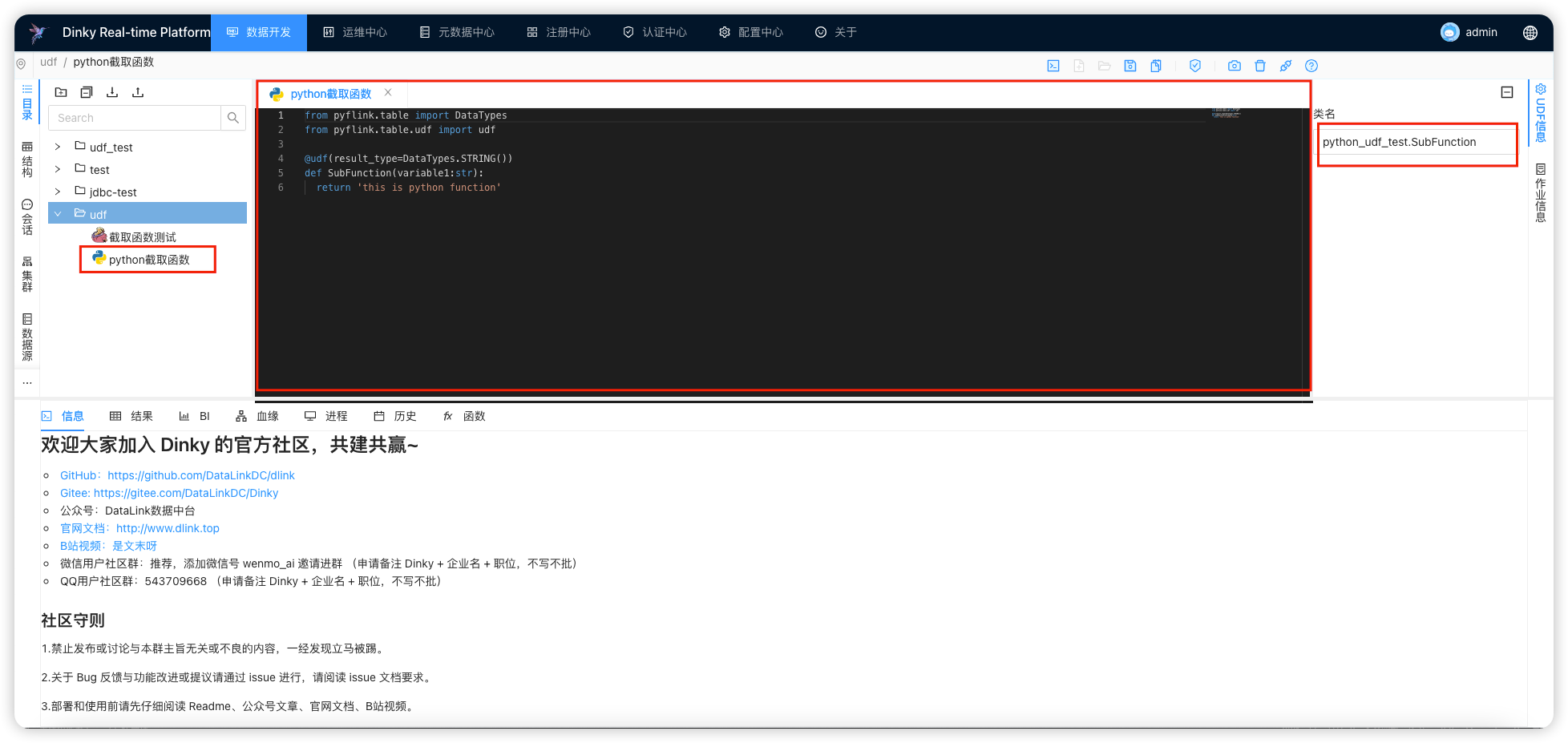
观察最右侧的类型,前缀就是 刚刚填的
名称
- 接下来创建一个
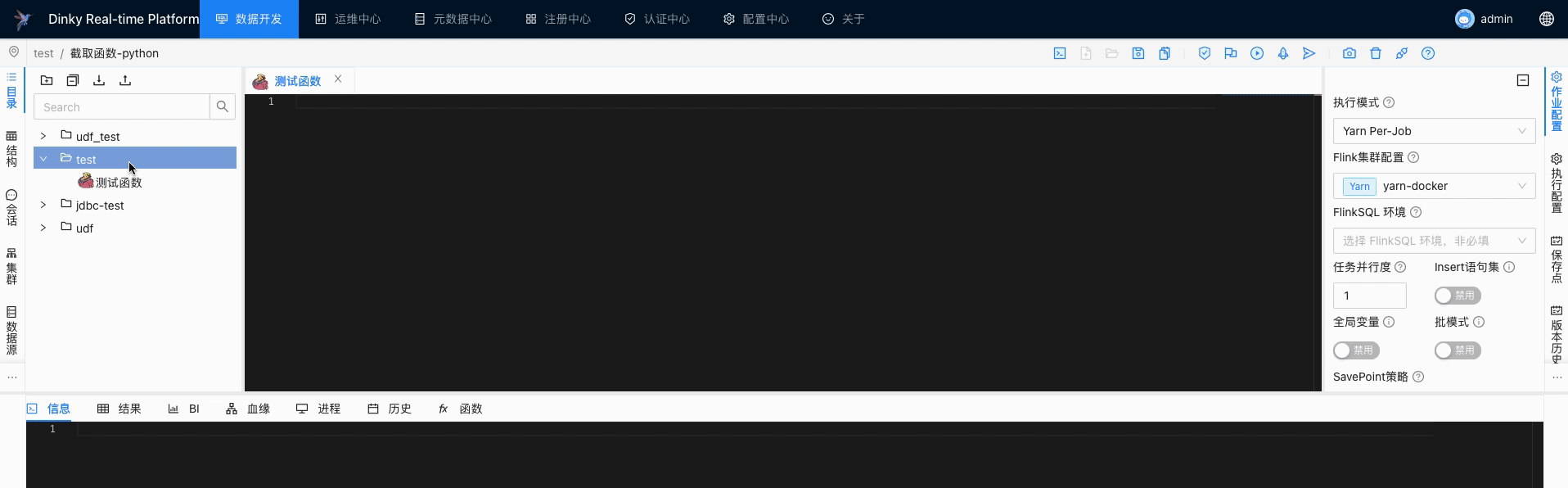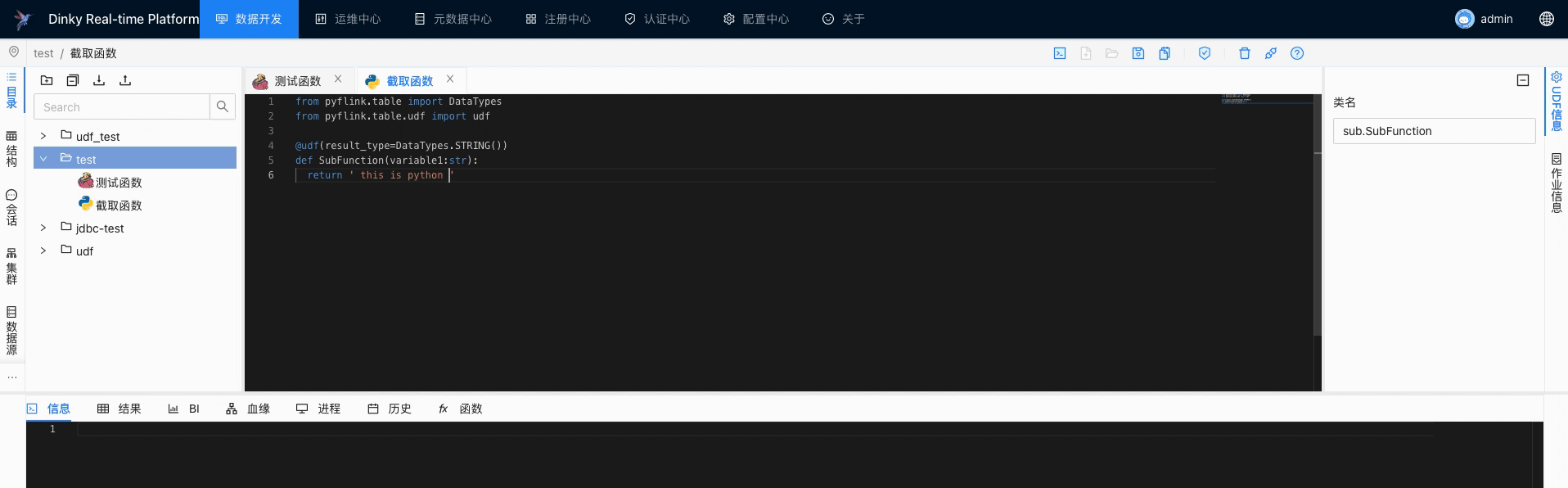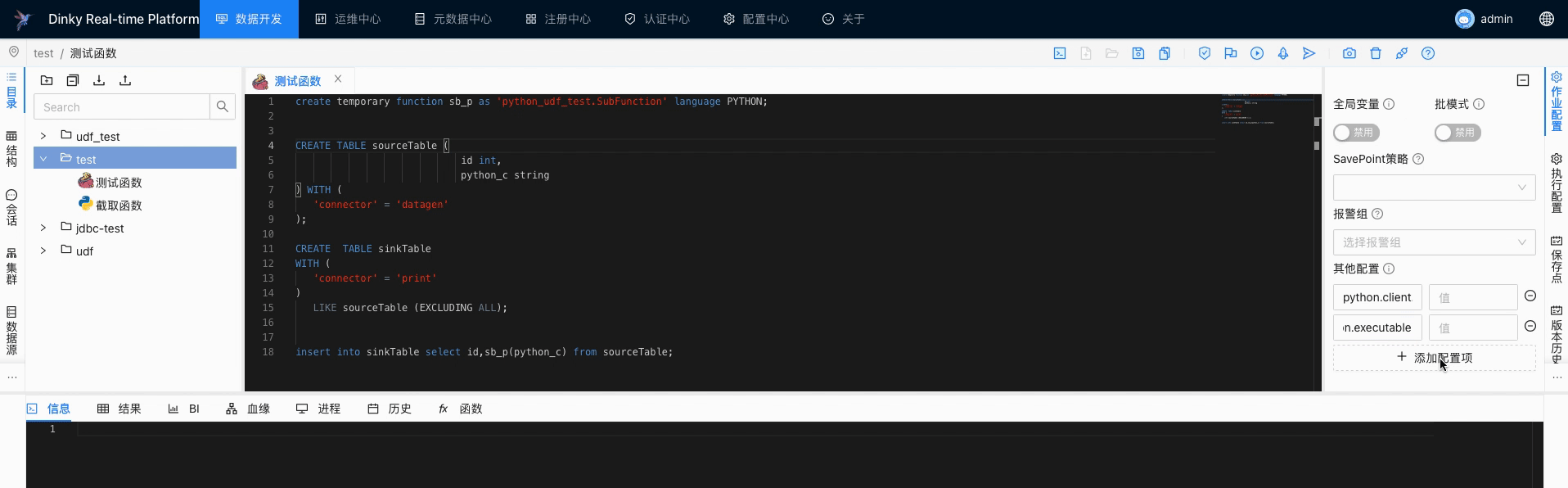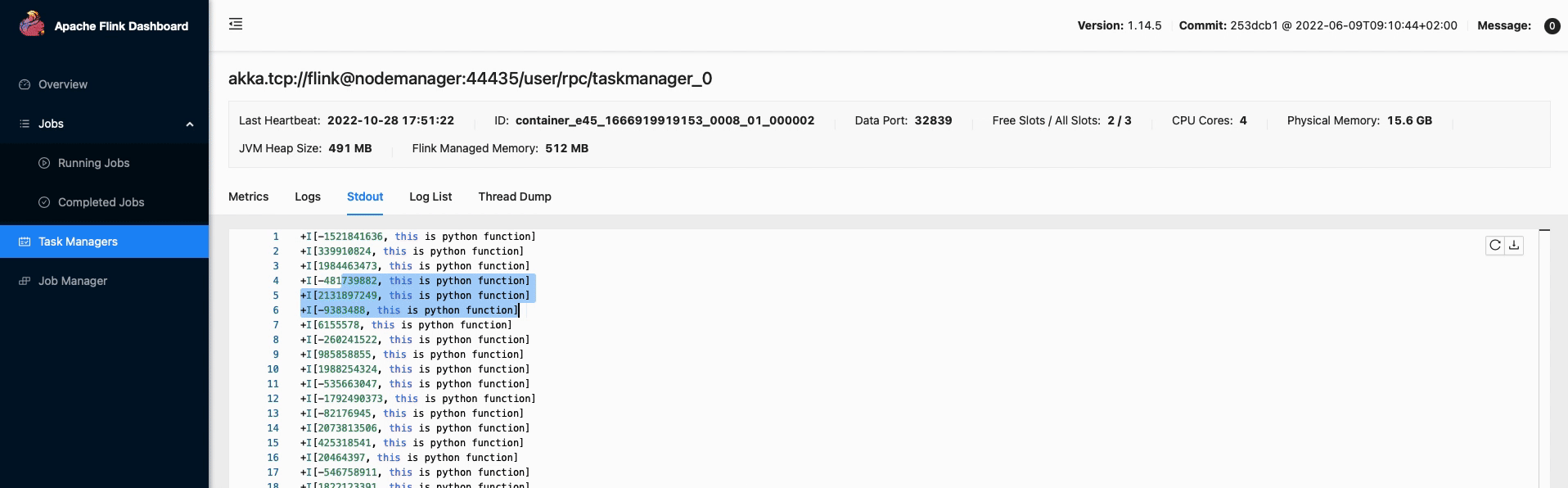
FlinkSql作业 创建函数与Java不太一样, 最后得指定语言 language PYTHON
create temporary function sb_p as 'python_udf_test.SubFunction' language PYTHON;
CREATE TABLE sourceTable (
id int,
python_c string
) WITH (
'connector' = 'datagen'
);
CREATE TABLE sinkTable
WITH (
'connector' = 'print'
)
LIKE sourceTable (EXCLUDING ALL);
insert into sinkTable select id,sb_p(python_c) from sourceTable;
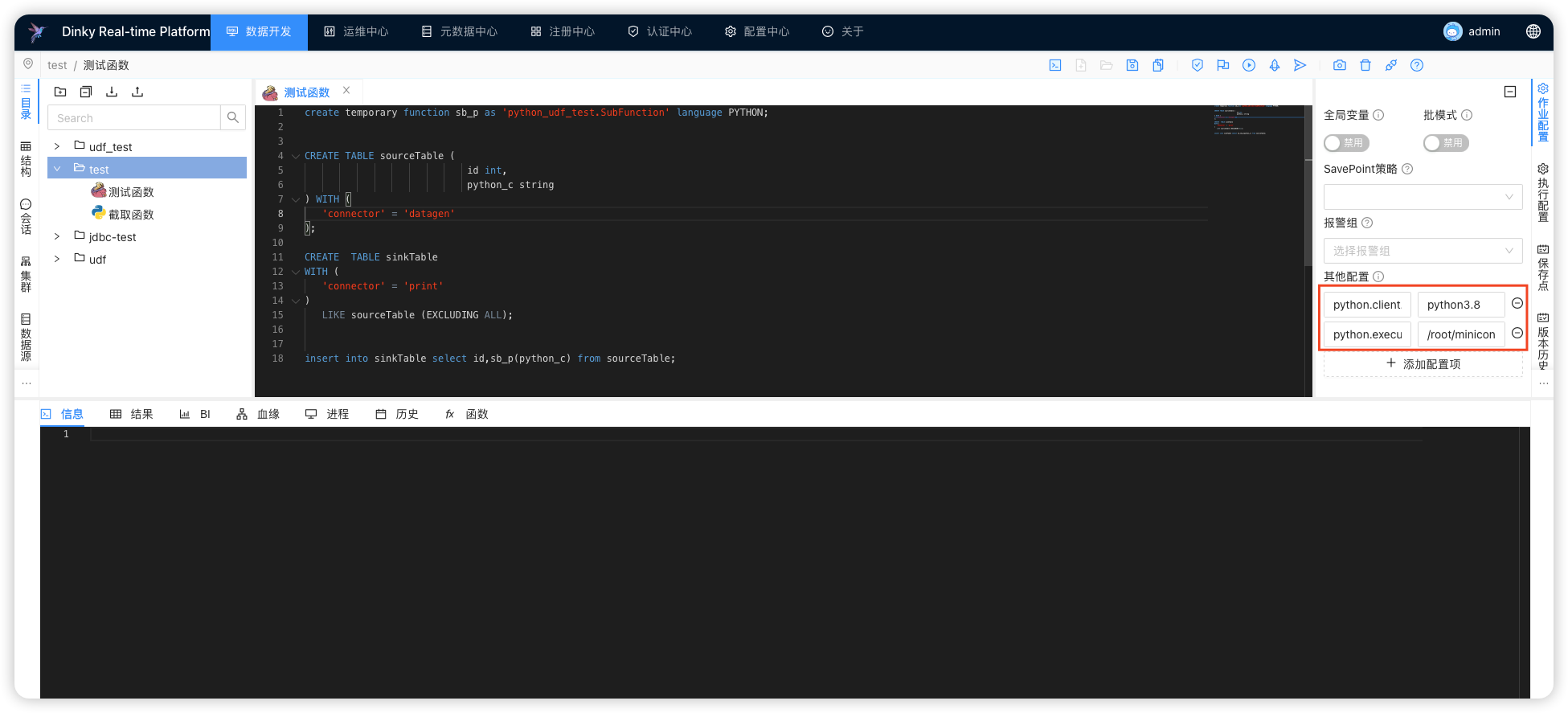
flink-conf.yml
python.client.executable: /root/miniconda3/bin/python3.8
python.executable: /root/miniconda3/bin/python3.8
这里需要注意的是,
flink-conf.yml得配置python的执行路径,python环境必须包含apache-flink,支持python3.6 - python3.8
python.executable是 NodeManager 环境的 python 执行路径
python.client.executable是 Dinky 当前机器所在的python环境特别注意,
yarn-application环境,2个参数均是hadoop集群 python3 的执行路径
- 执行,结果查看
动图演示