作业教程
作业开发
SQL 编辑器编辑的 FlinkSQL 作业,当前仅支持 Flink 11~16 版本的语法。
FlinkSQL 操作步骤
1.进入 Dinky 的 Data Studio
2.在左侧菜单栏,右键 目录
3.新建目录或作业
4.在新建文件的对话框,填写作业信息
| 参数 | 说明 | 备注 |
|---|---|---|
| 作业名称 | 作业名称在当前项目中必须保持 唯一 | |
| 作业类型 | 流作业和批作业均支持以下作业类型: FlinkSQL:支持SET、DML、DDL语法 FlinkSQLEnv:支持SET、DDL语法 | FlinkSQLEnv 场景适用于所有作业 的SET、DDL语法统一管理的场景, 当前FlinkSQLEnv 在SQL编辑器的语 句限制在1000行以内 |
5.在作业开发 SQL 编辑器,编写 DDL 和 DML 代码
示例代码如下:
--创建源表datagen_source
CREATE TABLE datagen_source(
id BIGINT,
name STRING
) WITH (
'connector' = 'datagen'
);
--创建结果表blackhole_sink
CREATE TABLE blackhole_sink(
id BIGINT,
name STRING
) WITH (
'connector' = 'blackhole'
);
--将源表数据插入到结果表
INSERT INTO blackhole_sink
SELECT
id ,
name
from datagen_source;
新建作业如下图:
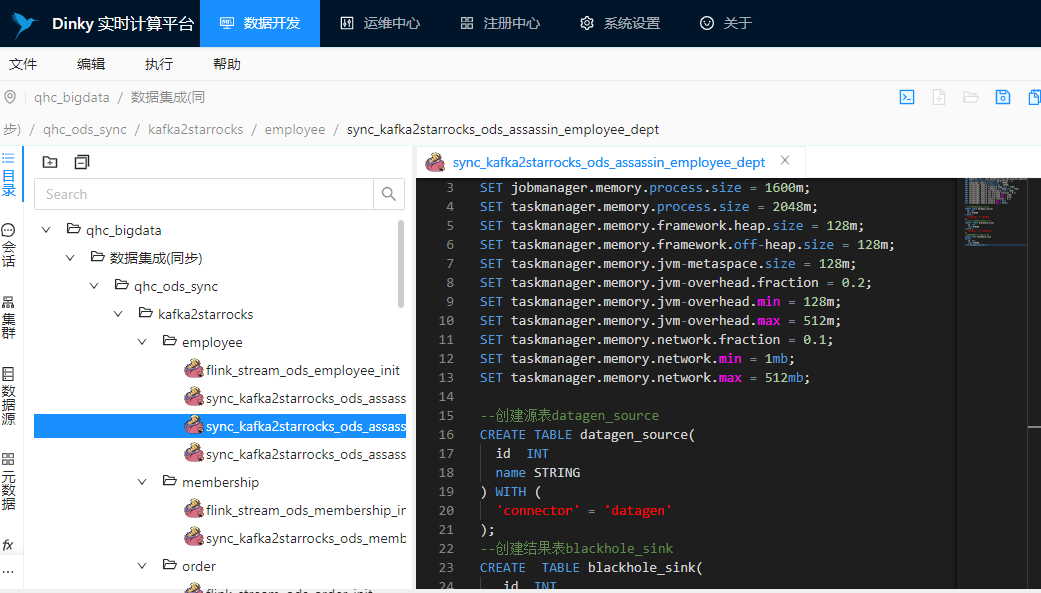
6.在作业开发页面右侧 执行配置,填写配置信息
| 类型 | 配置项 | 备注 |
|---|---|---|
| 作业配置 | 执行模式 | 区别详见用户手册数据开发中的作业概述 |
| 作业配置 | 集群实例 | Standalone 和 Session 执行模式需要选择集群实例,详见集群实例管理 |
| 作业配置 | 集群配置 | Per-Job 和 Application 执行模式需要选择集群配置,详见集群配置管理 |
| 作业配置 | FlinkSQL 环境 | 选择已创建的 FlinkSQLEnv,如果没有则不选 |
| 作业配置 | 任务并行度 | 指定作业级任务并行度,默认为 1 |
| 作业配置 | Insert 语句集 | 默认禁用,开启后将 SQL编辑器中编写的多个 Insert 语句合并为一个 JobGraph 进行提交 |
| 作业配置 | 全局变量 | 默认禁用,开启后可以使用数据源连接配置变量、自定义变量等 |
| 作业配置 | 批模式 | 默认禁用,开启后启用 Batch Mode |
| 作业配置 | SavePoint 策略 | 默认禁用,策略包括: 最近一次 最早一次 指定一次 |
| 作业配置 | 报警组 | 报警组配置详见报警管理 |
| 作业配置 | 其他配置 | 其他的 Flink 作业配置,具体可选参数,请参考 Flink 官网 |
作业配置如下图:
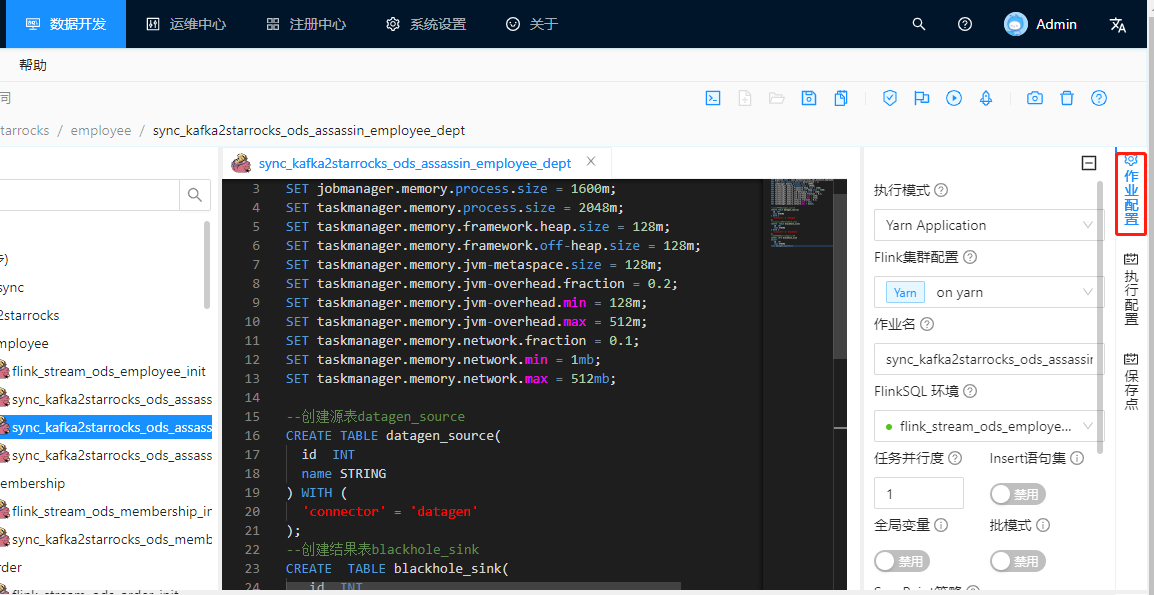
请及时手动保存作业信息,以免丢失
作业提交
功能说明
- 执行当前的 SQL: 提交执行未保存的作业配置,并可以同步获取 SELECT、SHOW 等执行结果,常用于 Local、Standalone、Session 执行模式;
- 异步提交: 提交执行最近保存的作业配置,可用于所有执行模式;
- 发布 发布当前作业的最近保存的作业配置,发布后无法修改;
- 上线 提交已发布的作业配置,可触发报警;
- 下线 停止已上线的作业,并触发 SavePoint;
- 停止 只停止已提交的作业;
- 维护 使已发布的作业进入维护状态,可以被修改;
- 注销 标记作业为注销不可用状态。
常用场景
- 查看 FlinkSQL 执行结果: 执行当前的 SQL。
- 提交作业: 异步提交。
- 上线作业: SavePoint 最近一次 + 上线。
- 下线作业: 下线。
- 升级作业: 下线后上线。
- 全新上线作业: SavePoint 禁用 + 上线。
Flink作业启动操作步骤
1.首先登录Dinky数据开发控制台
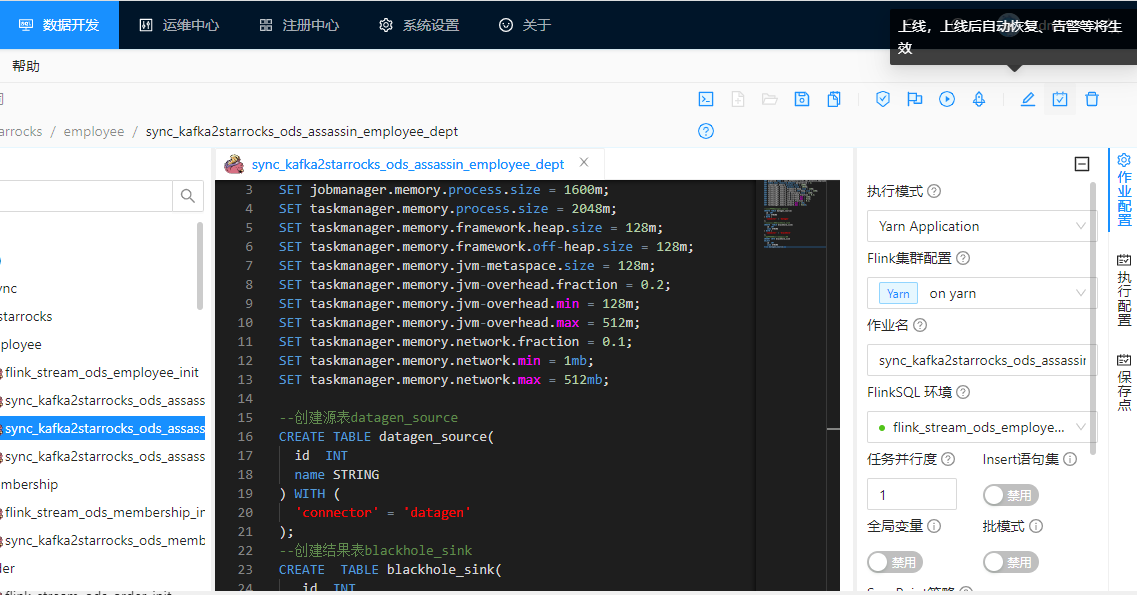
2.在左侧菜单栏选择目录 > 作业名称 > 检查当前的FlinkSql > 发布 > 上线
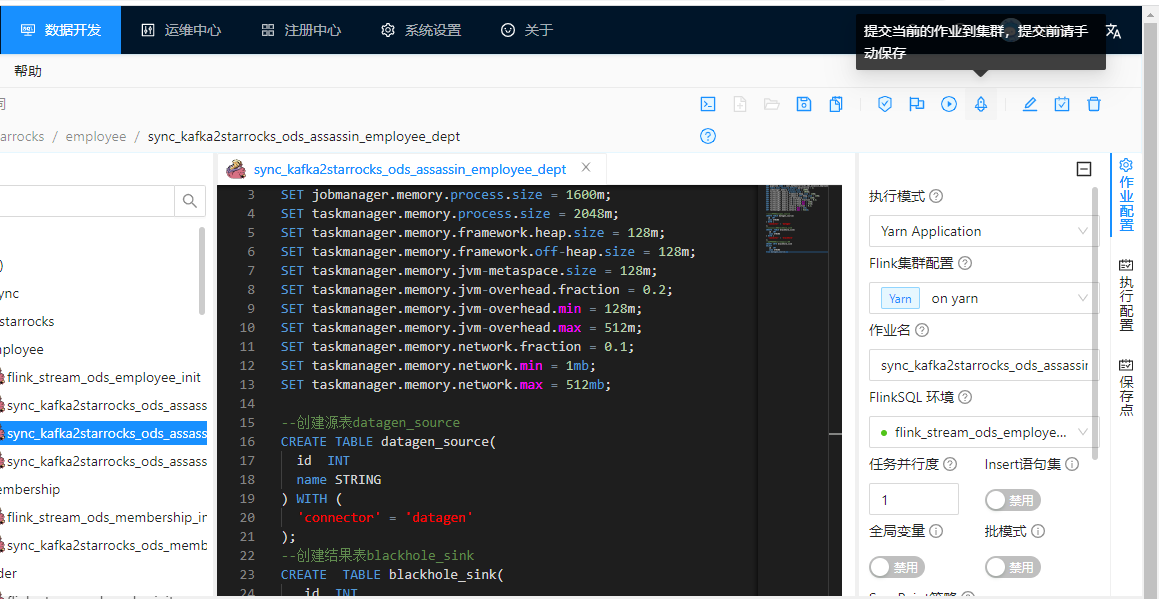
或者选择目录 > 作业名称 > 检查当前的FlinkSql > 异步提交
作业启动异步提交如下图:
作业启动发布上线如下图:
有关发布上线的详细内容,详见用户手册的运维中心
作业调试
可以选择使用 Standalone 或 Session 集群在开发测试环境对作业调试,如作业运行、检查结果等。配置 Standalone 或 Session 集群请参考注册中心中集群管理的集群实例管理。
也可以调试普通的 DB SQL 作业。
FlinkSQL作业调试步骤
1.进入 Data Studio
2.点击 目录 > 新建目录 > 新建作业
3.填写完作业信息后,单击 确认,作业类型选择 FlinkSQL
4.编写完整的 FlinkSQL 语句,包含 CREATE TABLE 等
示例代码如下:
--创建源表datagen_source
CREATE TABLE datagen_source(
id BIGINT,
name STRING
) WITH (
'connector' = 'datagen'
);
--将源表数据插入到结果表
SELECT
id BIGINT,
name STRING
from datagen_source
5.单击保存
6.单击语法检查
7.配置执行配置
| 配置项 | 说明 |
|---|---|
| 预览结果 | 默认开启,可预览 FlinkSQL 的执行结果 |
| 打印流 | 默认禁用,开启后将展示 ChangeLog |
| 最大行数 | 默认 100,可预览的执行结果最大的记录数 |
| 自动停止 | 默认禁用,开启后达到最大行数将停止作业 |
注意: 预览聚合结果如 count 等操作时,关闭打印流可合并最终结果。
8.单击执行当前的SQL
9.结果 或者 历史 > 预览数据 可以手动查询最新的执行结果
FlinkSQL 预览结果的必要条件
1.执行模式必须是 Local、Standalone、Yarn Session、Kubernetes Session 其中的一种;
2.必须关闭 Insert 语句集;
3.除 SET 和 DDL 外,必须只提交一个 SELECT 或 SHOW 或 DESC 语句;
4.必须开启 预览结果;
5.作业必须是提交成功并且返回 JID,同时在远程集群可以看到作业处于 RUNNING 或 FINISHED 状态;
6.Dinky 重启后,之前的预览结果将失效
DB SQL 调试
选择对应数据源,并书写其 sql 执行即可。